

| sitelink1 | |
|---|---|
| sitelink2 | |
| sitelink3 | |
| sitelink4 | |
| extra_vars5 | |
| extra_vars6 |
character encoding
컴퓨터에서는 모든 data가 내부적으로 0과 1의 이진수로 표현된다. 문자를 이진부호로 변환하는 것(혹은 변환 알고리즘)을 character encoding이라고 한다. UTF-8이나 UNICODE 혹은 ASCII와 같은 것들은 모두 이러한 character encoding 을 뜻한다.
characterset, charset
- 특정 문자에 대한 인코딩 방식 및 인코딩된 문자들의 집합을 의미한다.
- 인코딩에 따라 언어별 charset이 따로 있거나 같은 charset 안에 여러개의 언어가 포함될 수 있다.
- IBM에서 시작된 용어로 'encoding 집합'을 table화 한 것이다. (table화 : 목록을 만들고 일련 번호를 매긴다는 뜻이다.)
- IBM과 MicroSoft(MS)는 일반적으로 code page를 charset에 할당한다. 쉽게 말해 IBM/MS에서 "ks_c_5601-1987"과 같은 복잡한 명칭을 사용하기 번거로우니 알아보기 쉬운 번호를 붙여서 대신 사용하는 것이다. 즉, 한국어 charset의 하나인 "ks_c_5601-1987"을 "code page 949"번으로 부르는 것이다.
|
구분 |
Charset | CodePage |
| 한국어 | ks_c_5601-1987 | 949 |
| IBM EBCDIC(미국-캐나다) | IBM037 | 37 |
| OEM 미국 | IBM437 | 437 |
| IBM EBCDIC(국제) | IBM500 | 500 |
| 아랍어(ASMO 708) | ASMO-708 | 708 |
| 아랍어(DOS) | DOS-720 | 720 |
| 그리스어(DOS) | ibm737 | 737 |
| 발트어(DOS) | ibm775 | 775 |
| 서유럽어(DOS) | ibm850 | 850 |
| 중앙 유럽어(DOS) | ibm852 | 852 |
| OEM 키릴 자모 | IBM855 | 855 |
| 터키어(DOS) | ibm857 | 857 |
| OEM 다국 라틴 문자 I | IBM00858 | 858 |
| 포르투갈어(DOS) | IBM860 | 860 |
| 아이슬란드어(DOS) | ibm861 | 861 |
| 히브리어(DOS) | DOS-862 | 862 |
| 프랑스어(캐나다)(DOS) | IBM863 | 863 |
| 아랍어(864) | IBM864 | 864 |
| 북유럽어(DOS) | IBM865 | 865 |
| 키릴 자모(DOS) | cp866 | 866 |
| 현대 그리스어(DOS) | ibm869 | 869 |
| IBM EBCDIC(다국 라틴 문자-2) | IBM870 | 870 |
| 태국어(Windows) | windows-874 | 874 |
| IBM EBCDIC(현대 그리스어) | cp875 | 875 |
| 일본어(Shift-JIS) | iso-2022-jp | 932 |
| 중국어 간체(GB2312) | gb2312 | 936 |
| 한국어 | ks_c_5601-1987 | 949 |
| 중국어 번체(Big5) | big5 | 950 |
| IBM EBCDIC(터키어 라틴 문자-5) | IBM1026 | 1026 |
| IBM 라틴어-1 | IBM01047 | 1047 |
| IBM EBCDIC(미국-캐나다-유럽) | IBM01140 | 1140 |
| IBM EBCDIC(독일-유럽) | IBM01141 | 1141 |
| IBM EBCDIC(덴마크-노르웨이-유럽) | IBM01142 | 1142 |
| IBM EBCDIC(핀란드-스웨덴-유럽) | IBM01143 | 1143 |
| IBM EBCDIC(이탈리아-유럽) | IBM01144 | 1144 |
| IBM EBCDIC(스페인-유럽) | IBM01145 | 1145 |
| IBM EBCDIC(영국-유럽) | IBM01146 | 1146 |
| IBM EBCDIC(프랑스-유럽) | IBM01147 | 1147 |
| IBM EBCDIC(국제-유럽) | IBM01148 | 1148 |
| IBM EBCDIC(아이슬란드어-유럽) | IBM01149 | 1149 |
| 유니코드 | utf-16 | 1200 |
| 유니코드(Big-Endian) | unicodeFFFE | 1201 |
| 중앙 유럽어(Windows) | windows-1250 | 1250 |
| 키릴 자모(Windows) | windows-1251 | 1251 |
| 서유럽어(Windows) | Windows-1252 | 1252 |
| 그리스어(Windows) | windows-1253 | 1253 |
| 터키어(Windows) | windows-1254 | 1254 |
| 히브리어(Windows) | windows-1255 | 1255 |
| 아랍어(Windows) | windows-1256 | 1256 |
| 발트어(Windows) | windows-1257 | 1257 |
| 베트남어(Windows) | windows-1258 | 1258 |
| 한국어(조합) | Johab | 1361 |
| 서유럽어(Mac) | macintosh | 10000 |
| 일본어(Mac) | x-mac-japanese | 10001 |
| 중국어 번체(Mac) | x-mac-chinesetrad | 10002 |
| 한국어(Mac) | x-mac-korean | 10003 |
| 아랍어(Mac) | x-mac-arabic | 10004 |
| 히브리어(Mac) | x-mac-hebrew | 10005 |
| 그리스어(Mac) | x-mac-greek | 10006 |
| 키릴 자모(Mac) | x-mac-cyrillic | 10007 |
| 중국어 간체(Mac) | x-mac-chinesesimp | 10008 |
| 루마니아어(Mac) | x-mac-romanian | 10010 |
| 우크라이나어(Mac) | x-mac-ukrainian | 10017 |
| 태국어(Mac) | x-mac-thai | 10021 |
| 중앙 유럽어(Mac) | x-mac-ce | 10029 |
| 아이슬란드어(Mac) | x-mac-icelandic | 10079 |
| 터키어(Mac) | x-mac-turkish | 10081 |
| 크로아티아어(Mac) | x-mac-croatian | 10082 |
| 중국어 번체(CNS) | x-Chinese-CNS | 20000 |
| TCA 대만 | x-cp20001 | 20001 |
| 중국어 번체(Eten) | x-Chinese-Eten | 20002 |
| IBM5550 대만 | x-cp20003 | 20003 |
| TeleText 대만 | x-cp20004 | 20004 |
| Wang 대만 | x-cp20005 | 20005 |
| 서유럽어(IA5) | x-IA5 | 20105 |
| 독일어(IA5) | x-IA5-German | 20106 |
| 스웨덴어(IA5) | x-IA5-Swedish | 20107 |
| 노르웨이어(IA5) | x-IA5-Norwegian | 20108 |
| US-ASCII | us-ascii | 20127 |
| T.61 | x-cp20261 | 20261 |
| ISO-6937 | x-cp20269 | 20269 |
| IBM EBCDIC(독일) | IBM273 | 20273 |
| IBM EBCDIC(덴마크-노르웨이) | IBM277 | 20277 |
| IBM EBCDIC(핀란드-스웨덴) | IBM278 | 20278 |
| IBM EBCDIC(이탈리아) | IBM280 | 20280 |
| IBM EBCDIC(스페인) | IBM284 | 20284 |
| IBM EBCDIC(일본어 가타카나) | IBM290 | 20290 |
| IBM EBCDIC(프랑스) | IBM297 | 20297 |
| IBM EBCDIC(아랍어) | IBM420 | 20420 |
| IBM EBCDIC(그리스어) | IBM423 | 20423 |
| IBM EBCDIC(히브리어) | IBM424 | 20424 |
| IBM EBCDIC(한국어 확장) | x-EBCDIC-KoreanExtended | 20833 |
| IBM EBCDIC(태국어) | IBM-Thai | 20838 |
| 키릴 자모(KOI8-R) | koi8-r | 20866 |
| IBM EBCDIC(아이슬란드어) | IBM871 | 20871 |
| IBM EBCDIC(키릴 자모 러시아어) | IBM880 | 20880 |
| IBM EBCDIC(터키어) | IBM905 | 20905 |
| IBM 라틴어-1 | IBM00924 | 20924 |
| 일본어(JIS 0208-1990 및 0212-1990) | EUC-JP | 20932 |
| 중국어 간체(GB2312-80) | x-cp20936 | 20936 |
| 한국어(완성) | x-cp20949 | 20949 |
| IBM EBCDIC(키릴 자모 세르비아어-불가리아어) | cp1025 | 21025 |
| Ext Alpha 소문자 | x-cp21027 | 21027 |
| 키릴 자모(KOI8-U) | koi8-u | 21866 |
| 서유럽어(ISO) | iso-8859-1 | 28591 |
| 중앙 유럽어(ISO) | iso-8859-2 | 28592 |
| 라틴어 3(ISO) | iso-8859-3 | 28593 |
| 발트어(ISO) | iso-8859-4 | 28594 |
| 키릴 자모(ISO) | iso-8859-5 | 28595 |
| 아랍어(ISO) | iso-8859-6 | 28596 |
| 그리스어(ISO) | iso-8859-7 | 28597 |
| 히브리어(ISO-Visual) | iso-8859-8 | 28598 |
| 터키어(ISO) | iso-8859-9 | 28599 |
| 에스토니아어(ISO) | iso-8859-13 | 28603 |
| 라틴어 9(ISO) | iso-8859-15 | 28605 |
| 히브리어(ISO-Logical) | iso-8859-8-i | 38598 |
| 일본어(JIS) | iso-2022-jp | 50220 |
| 일본어(JIS-Allow 1 byte Kana) | iso-2022-jp | 50221 |
| 일본어(JIS-Allow 1 byte Kana - SO/SI) | iso-2022-jp | 50222 |
| 한국어(ISO) | euc-kr | 50225 |
| 중국어 간체(ISO-2022) | x-cp50227 | 50227 |
| 일본어(EUC) | euc-jp | 51932 |
| 중국어 간체(EUC) | EUC-CN | 51936 |
| 한국어(EUC) | euc-kr | 51949 |
| 중국어 간체(HZ) | hz-gb-2312 | 52936 |
| 중국어 간체(GB18030) | GB18030 | 54936 |
| 유니코드(UTF-7) | utf-7 | 65000 |
| 유니코드(UTF-8) | utf-8 | 65001 |
American Standard code Information Interchange(ASCII)
- 1967년에 표준으로 제정된 영문 알파벳을 사용하는 인코딩이다.
- 7bit를 사용하여 33개의 출력 불가능한 제어 문자와 95개의 출력 가능한 문자들로 이루어졌다.
- 출력 불가능한 문자들은 과거에 표준 제정 시절에 사용되던 것으로 현재는 대부분 사용되지 않는다.
- 출력 가능한 문자 : 52개의 영문 알파벳 대소문자, 10개의 숫자, 32개의 특수문자, 1개의 공백문자
- ASCII 기반의 확장 encoding이 많이 있다.
- 기존 인코딩의 한계를 극복하고 전 세계의 모든 문자를 일관되게 표현할 수 있도록 설계된 산업 표준이다.
- 기존 인코딩은 규모와 범위면에서 한정되어 다국어 환경에서는 같은 인코딩이라 하더라도 서로 호환되지 않는 문제점이 있다. 예컨데 일본어 인코딩만 적용된 MP3 플레이어를 사용하는 경우 한글제목의 가요는 깨져서 보이게 된다.
- ISO 10646 charset, encoding, 문자 정보 data base 및 문자를 다루기 위한 알고리즘등을 포함한다.
UTF-8 (UCS Transformation Format - 8bit)
- UCS는 Universal Character Set의 줄임말이다.
- Unicode를 따르는 인코딩 방식 중 하나이다.
- 한 문자를 나타내기 위해 1byte에서 4byte까지를 사용한다.
- 장점
- ASCII 인코딩과 하위 호환성이 있다.
- UTF-16과 함께 XML 문서의 표준 인코딩이다.
- 다른 인코딩과의 상호변환이 용이하다.
- 바이트 단위의 문자열 검색 알고리즘을 그대로 사용할 수 있다.
- UTF-8 문자열임을 확인하기가 용이하다.
- UTF-8 문자열 내에 NULL이 없으므로 C 언어의 문자열 함수를 그대로 사용할 수 있다.
- 단점
- 일반적으로 다른 인코딩에 비해 크기가 크다.
- 한 문자를 표현하기 위해 1byte~n byte가 사용되는 인코딩 방법를 의미한다.
- "특정 인코딩"을 의미하는 것이 아니다.
- UTF-8도 MBCS 방식의 인코딩이다.
- 문자를 표현하는데 2byte(Win32, Win64, Java, .Net Framework 기준)를 사용하는 인코딩 방법을 의미한다.
- 흔히 Unicode와 WBCS를 같은 의미로 사용하는데 이는 바르지 않다.
- Unicode는 앞서 설명한 바와 같이 다국어 지원을 위한 표준 규약일 뿐 어떤 인코딩 자체를 특정하는 것은 아니기 때문이다. (UTF-8의 경우 Unicode이면서 MBCS이다.)
(c++로) unicode를 multi-byte character로 변환한다는 의미
Windows의 Code page 파일...
WIndows에서 Code Page 변환을 위한 파일은
Windows/System32 폴더 아래에 존재합니다.
지원하는 Code page에 따라서 C_xxxx.nls 와 같은 형태로 저장되어 있습니다.
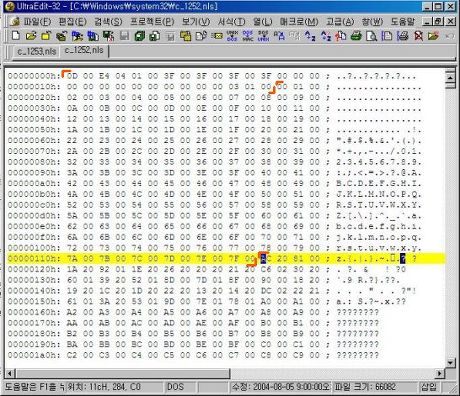
일단 분석이 용이한 Code Page를 위주로 보면 다음과 같습니다.
CP_1252 (Windows Latin 1) Code Page와 관련된 파일은 C_1252.nls 파일입니다.
CP_1252의 경우 0x00 ~ 0x7F 까지는 ASCII 영역이고 0x80 ~ 0xFF 까지가 Latin 문자를 표시하기 위한 영역입니다.
보통 Code Page는 Unicode로 변환하기 위하여 사용되므로 한개의 문자는 2Byte(Unicode 값)가 필요합니다.
즉 이점을 이용해서 C_1252.nls 파일을 보면
1) 헤더 (28 Byte)
정확한 사용 용도는 알 수 없으나 3, 4 번째 데이터(0x04E4 : 1250)는 코드 페이지값을 나타냄
2) ANSI -> Unicode Table (512 Byte)
처음 256 Byte는 0x00 ~ 0x7F 영역을 위한 Unicode입니다.
다음 256 Byte는 0x80 ~ 0xFF 영역을 위한 Unicode입니다.
3) Dummy (6 Byte)
4) Unicode -> ANSI (65536 Byte)
16Bit Unicode를 8Bit ANSI 코드로 변경하는 것이기 때문에 모두 65536개의 데이터가 순서대로 저장되어 있습니다. 따라서 만약 Unicode 0x013d에 대한 ANSI 코드를 찾으려면 0x013d + 0x222 = 0x035f 에 해당하는 주소의 데이터를 읽으면 됩니다.
결론적으로 우리가 필요한 것은 파일의 처음으로 부터 284바이트 이후(0x0000011C) 부터입니다.
정리하면 다음같이 변환되게 하면 됩니다.
0x80 -> 0x20AC
0x81 -> 0x0081
0x82 -> 0x201A
0x83 -> 0x0192
0x84 -> 0x201E
...
실제 c_xxxx.nls 파일에서 키릴문자나 한국어, 중국어, 일본어 등은 2Byte 코드 체계이므로 위와 같은 분석으로는 분석이 안됩니다. 헤더 정보도 추가 정보가 다르게 되어 있음을 확인할 수 있습니다.
다른 c_xxxx.nls 파일도 유사한 방법으로 데이터를 추출해서 사용할 수 있습니다.
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 65 |
Canvas 비트맵 그리기
| 황제낙엽 | 2016.08.22 | 42 |
| 64 |
Canvas 그라디언트 그리기
| 황제낙엽 | 2016.08.22 | 38 |
| 63 |
Canvas 텍스트 그리기
| 황제낙엽 | 2016.08.22 | 20 |
| 62 |
Canvas 곡선 그리기
| 황제낙엽 | 2016.08.22 | 424 |
| 61 |
Canvas 다각형 그리기
| 황제낙엽 | 2016.08.22 | 111 |
| 60 |
Canvas 사각형 그리기
| 황제낙엽 | 2016.08.22 | 30 |
| 59 |
Canvas 시작하기
| 황제낙엽 | 2016.08.22 | 23 |
| 58 | HTML5 개발을 도와주는 도구들 | 황제낙엽 | 2014.04.04 | 41 |
| » |
encoding, charset, code page, UTF-8, UNICODE ...
| 황제낙엽 | 2013.08.07 | 731 |
| 56 | document.domain (from mozilla.org) | 황제낙엽 | 2013.03.13 | 407 |
| 55 |
우리은행 웹 접근성 가이드
| 황제낙엽 | 2013.03.08 | 86 |
| 54 | 모든 브라우저에서 동작하는 opacity 설정 코드 | 황제낙엽 | 2013.02.14 | 67 |
| 53 | DXImageTransform.Microsoft.AlphaImageLoader 와 file dialog | 황제낙엽 | 2013.01.28 | 142 |
| 52 | Gradient 와 Background-Image 동시 적용 방안 | 황제낙엽 | 2013.01.11 | 117 |
| 51 |
그라디언트와 다중 배경 (gradient)
| 황제낙엽 | 2013.01.11 | 52 |
| 50 |
CSS Gradient Background Maker
| 황제낙엽 | 2013.01.11 | 25 |
| 49 | Radius, Gradient, Padding | 황제낙엽 | 2013.01.11 | 74 |
| 48 | 스타일-보더 테스트 관련 레퍼런스 | 황제낙엽 | 2013.01.04 | 248 |
| 47 | Vector Markup Language | 황제낙엽 | 2012.12.20 | 28 |
| 46 | ScrollBar의 출력형태 | 황제낙엽 | 2012.09.14 | 54 |