| sitelink1 | http://blog.naver.com/redblue_six?Redire...39966vvvvv |
|---|---|
| sitelink2 | http://www.cresc.co.jp/tech/java/URLenco...coding.htm |
| sitelink3 | |
| sitelink4 | |
| extra_vars4 | |
| extra_vars5 | |
| extra_vars6 |
페이지가 utf-8 로 설정되는 것만으로 javascript 이 한글처리는 온전하지 못하다.
javascript 는 서버와 ajax를 통하여 데이터를 주고받을 수 있기 때문에 주고받는 데이터에 대해서도 한글처리가 별도로 필요하다.
다음의 문서를 참조하여 Ajax 와 Java 와의 한글데이터 정보 처리에 대해 살펴보자.
1. 번역문
JavaScript 에 있어서의URL encode의 처리
이 메모는,JavaScript 그리고 쿠키를 처리하는 경우의 포인트를 나타내 보여,URL encode에 관련되는 트러블을 회피해 주시는 것을 목적으로 하고 있습니다.급한 것(분)편은3 장과4 아키라를 파견해 읽어 받아 상관하지 않습니다.또한 이 메모는 가능한 한IE 그리고 봐 주세요.
목차
3. 3 JavaScript 에 있어서의escape() (와)과unescape() 함수
4. 4 JavaScript 에 있어서의encodeURI ,decodeURI ,encodeURIComponent ,decodeURIComponent
HTML 텍스트 이외에 웹·서버가 브라우저에 정보를 건네주는 수단은,HTTP 응답 메세지의 헤더 부분에 그 정보를 세트 하는 것입니다(보디 부분에는 통상HTML 텍스트가 들어갑니다).서버측에게서는 쿠키 설정의 헤더행이나 스스로 만든 특별한 헤더행에 정보를 세트 할 수 있습니다.이것들은(이름, 값)의 페어의 형식을 취합니다.
HTML 텍스트외에서 건네받는 정보는, 브라우저 화면에 표시되지 않기 때문에, 표시의 목적 이외의 세션 관리 등에 사용됩니다.서브 렛에 있어서의 쿠키에 의한 세션 유지의 메카니즘은, 바야흐로 이 특성을 이용한 것입니다.세션 이외에도 클라이언트와의 각종 관리 정보(브라우저의 타입이나 버젼, 유저 정보 등), 암호화를 위한 정보(열쇠나 방식등)의 교신이라고 하는 응용도 생각할 수 있습니다.또 보낸 쿠키는 클라이언트에 축적되므로, 반복 표시나 화면에 공통의 정보를 최초로 쿠키로 보내 버리는 것도 가능합니다.또, 폼에 표시하지 않고 필요한 정보를 서버에 돌려줄 수도 있습니다.
예를 들어Tomcat 등의 서브 렛·엔진이 세션 유지에 사용하고 있다( “jsessionid ”, ID) 의 종류의 메카니즘 이외에, 더 상세하게 그 세션의 정보(유저의 이름등)를 클라이언트로 유지해, 필요하게 응해 이것을 표시하는 등이 가능하게 됩니다.
JavaScript 냄새나서는,HTTP 응답 메세지의 헤더행을 직접 꺼내는 기능은 유감스럽지만 없습니다.그렇지만Window.document.cookie 오브젝트를 사용하고, 쿠키를 개입시킨 정보의 교환이 가능합니다.그렇지만, 후술과 같이HTTP 메세지의 헤더행은URL encode 되지 않습니다.ASCII 캐릭터 세트만으로 끝나는 구미와 달리 우리와 같이2 아르바이트의 캐릭터 세트를 표준적으로 사용하는 경우는,URLencode에 주의하지 않으면 안됩니다.여러분이 고민해 또 문제를 일으키기 쉬운 것은 이 점이지요.
이 메모는,JavaScript 그리고 쿠키를 처리하는 경우의 포인트를 나타내 보여,URL encode에 관련되는 트러블을 회피해 주시는 것을 목적으로 하고 있습니다.
1. 쿠키와URL 인코딩
쿠키와URL 인코딩의 기본적인 지식이 필요하게 되기 때문에, 최초로 그 포인트를 실례로 나타내 보이겠습니다.
통상cookie (은)는 어플리케이션·서버가HTTP 응답의 패킷의 헤더 부분에 세트 하고 브라우저에 건네줍니다.예를 들면IBM 의 서브 렛·엔진은 다음과 같은HTTP 의 헤더행을HTTP 응답에 붙여 세션(서비스와 클라이언트와의 대응의 식별)의 유지를 이라고 깔때기 하고 있습니다.이 예()에서는sessionid 그렇다고 하는 「이름」의 변수와LV ··되는 「값」의 조를 건네주고 있습니다.
Set-Cookie: sessionid=LV140HYAAAABZQ....;Path=/
이와 같이cookie 하HTTP 패킷의 헤더행에 의해서 전달되므로,2 아르바이트 문자나 ”; ” (이)나 ”= ” 등이 위험한(프로토콜 상의미를 가진다) 문자를 포함한 「이름」이나 「값」을 가진다cookie (을)를 클라이언트에 건네줄 때는, 위험한 아르바이트 문자를 포함하지 않게URL encode 하고, 아르바이트열로서 전달하지 않으면 되지 않습니다.
멀티 바이트 문자를 서브 렛·엔진은 과연 이것을 인식해 자동적으로URL encode 해 주는 것일까 실험해 봅시다.
다음의 서브 렛은 넷상(http://ash.jp/java/hellocookie.htm) 에서 공개되고 있던 프로그램에 일부 손본 것입니다.이 프로그램은 서브 렛에 있어서의 쿠키 처리에 관한 힌트가 들어가 있기 때문에, 대충 이해해 주세요.
import java.io.*;
import java.net.*;
import javax.servlet.*;
import javax.servlet.http.*;
/** 쿠키 읽고 쓰기 서브 렛 **/
public class HelloCookie0 extends HttpServlet {
public void doGet (HttpServletRequest req, HttpServletResponse res) throws ServletException, IOException {
PrintWriter out;
Cookie[] cookies;
Cookie cookie;
// Cookie 의 취득
cookies = req.getCookies();
cookie = null;
if (cookies != null){
for(int i=0; i < cookies.length; i++) {
cookie = cookies[i];
if (cookie.getName().equals("HelloCookie")) { break; }
}
}
res.setContentType("text/html; charset=Shift_JIS");
out = res.getWriter();
HttpSession session = req.getSession(); // Session 의 취득과 써
session.setMaxInactiveInterval(600); // 10 분간 유효
if (session.isNew()) { // Cookie 의 기재
cookie = new Cookie("HelloCookie", "Hello World!");
cookie.setMaxAge(60); // 유효기간은1 분에 끊어진다
res.addCookie(cookie);
out.println("<html><body>");
out.println("<h1>Write Cookie</h1>");
out.println("<p> 리로드 해 주세요.</p>");
out.println("</body></html>");
} else { // Cookie 의 표시
out.println("<html><body>");
out.println("<h1>");
for(int i=0; i < cookies.length; i++) {
cookie = cookies[i];
out.println(cookie.getName()+" : "+ new String(cookie.getValue().getBytes("8859_1"), "Shift_JIS"));
out.println("<BR>");
}
out.println("</h1>");
out.println("<p>Cookie 의 샘플(HelloCookie0.java )</p>");
out.println("</body></html>");
}
}
}
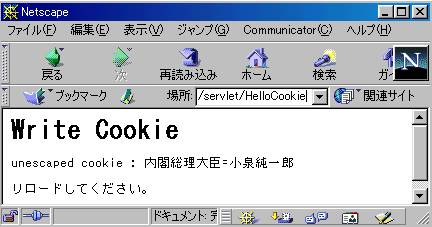
이 프로그램으로cookie = new Cookie("HelloCookie", "Hello World!"); 그렇다고 하는 행의 「값」의 문자열에 한자나 위험한 문자를 설정하면 서브 렛·엔진은 어떠한 응답 패킷을 송신할까 시험해 봅시다.
a) ”Hello 일본! ” (와)과 바꾸어telnet 의 소프트웨어로 액세스 하면 다음과 같은 결과를 얻을 수 있습니다.최초의2 행(공백행도 포함한다)은telnet 하지만 보냈다HTTP 요구 메세지입니다.그 이후가 서브 렛·엔진(여기에서는Tomcat )(이)가 돌려주었다HTTP 응답 메세지입니다.전반이 헤더 부분, 마지막4 행이 보디 부분입니다.그런데HTTP 응답의 헤더 부분을 보면,Set-Cookie 되는 헤더행이2행 존재하는 것이 분 빌려지요.처음은 서브 렛이 작성한 것으로, 후의 것은 서브 렛·엔진이 세션 유지를 위해 작성한 것입니다.따라서, 브라우저로 해 보면,2 개의 쿠키가 건네받았다고 하는 것이 됩니다.브라우저측에서 이러한 쿠키에 아무것도 변경을 더하지 않으면, 서브 미트·버튼등에서 이URL (을)를 재차 액세스 했을 때에는, 이러한 쿠키는 유효기간이 끊어지지 않으면 그대로 서버에 돌려주어집니다.
GET /examples/servlet/HelloCookie0 HTTP/1.0
HTTP/1.1 200 OK
Content-Type: text/html; charset=Shift_JIS
Connection: close
Date: Wed, 30 Oct 2002 03:45:24 GMT
Server: Apache Tomcat/4.0.4-b3 (HTTP/1.1 Connector)
Set-Cookie: HelloCookie=Hello 일본!;Expires=Wed, 30-Oct-2002 03:50:25 GMT
Set-Cookie: JSESSIONID=BAFB93DD6C7848751C369747B316DB6C;Path=/examples
<html><body>
<h1>Write Cookie</h1>
<p> 리로드 해 주세요.</p>
</body></html>
b) 그런데 이HTTP 응답 메세지를 보면,telnet 의 대응문자 세트를Shift_JIS (으)로 했으므로, “Hello일본! ”의 부분은 문자가 변해를 일으키지 말고 올바르게 읽어내지고 있습니다.또,IE(v6) 그리고http://localhost:8080/examples/servlet/HelloCookie0 (와)과 액세스 해, 여러분의PC의C:WINDOWSCookies (을)를 조사하면, 이 쿠키가 문자가 깨지지 않고 수리되고 있는 것이 확인할 수 있겠지요.그렇지만, 실은 이것은, 우연히 잘 되었다고 할 뿐(만큼)입니다. ” 일본 ” 그렇다고 하는 문자는Shift_JIS (으)로서 헤더에 들어가 있습니다만, 이 아르바이트열의 어느 아르바이트도ASCII 의 「위험한 문자」에 떨어지지 않기 때문입니다.또한, 이 실험에서는 로컬의 호스트를 사용하고 있어 네트워크를 개입시키고는 있지 않습니다.네트워크의 노드에 따라서는(낡은 시스템입니다만)7 비트 밖에 전송되지 않고, 최상위의1 비트(MSB) (은)는 잘못 검출이나 동기등의 목적으로 사용되고 있는 것도 있습니다.그러한 노드를 이HTTP 메세지가 통과하면, 당연히 문자가 변해를 일으켜 버립니다.
c) 위험한 문자를 포함한 문자열이 쿠키의 「값」의 장소에 세트 되면 어떻게 될까요?쿠키의 「이름」에 위험한1 아르바이트 문자가 포함되어 있으면 서브 렛·엔진은 예외를 일으키도록(듯이) 규정되고 있습니다만, 「값」에는 그러한 제약이 어떤 (뜻)이유일까 규정되고 있지 않습니다.시험삼아 ” AAA ;B%BB ” (와)과 스페이스와 세미콜론을 포함한 문자를 출력해 보자.telnet 그리고 이 서브 렛을 호출해 보면 다음과 같은HTTP 응답 패킷을 관찰할 수 있습니다.
HTTP/1.1 200 OK
Content-Type: text/html; charset=Shift_JIS
Connection: close
Date: Tue, 22 Oct 2002 04:39:25 GMT
Server: Apache Tomcat/4.0.4-b3 (HTTP/1.1 Connector)
Set-Cookie: HelloCookie=Hello AAA;B%BB;Expires=Tue, 22-Oct-2002 04:44:26 GMT
이하 생략
이것을 브라우저(IE6) (은)는 어떻게 수중에 넣었는지를Explorer 그리고 보면C:WINDOWSCookies의 디렉토리에 기록되고 있는 파일은 다음과 같은 텍스트가 되어 있습니다.즉 스페이스는 받아들였지만 세미콜론 이후는 쿠키로서는 받아들이지는 않습니다.세미콜론은 인터넷의 세계에서는 「단락 문자」입니다.
HelloCookie
AAA
localhost/examples/servlet/
1024
1088345728
29522332
2383813024
29522331
*
다음의 장으로 자세하게 설명합니다만,URL 인코딩은MSB 하지만1 의 아르바이트나, 인터넷상에서 특별한 의미를 가진다7 비트ASCII 문자를,7 비트ASCII 문자를 사용해 혼란시키지 않고 보내기 위한 구조입니다.
지금까지의 실험으로부터 분 덧없는 세상 게, 쿠키의 송신에 임하고는 이름, 값이라고도URLencode 해 보내는 것이 추천 됩니다. 이것은NetScape 회사의 해설서에서도 추천 되고 있는 것입니다.또한 서브 렛·엔진이 세션 유지를 위해cookie (을)를 세트 할 때는URL encode 하고 있지는 않다고, 할까URL encode의 필요가 없는 문자 밖에 사용하고 있지 않습니다(URL 변환해도 어떤 변화도 생기지 않습니다).telnet 등에서 검사하기 쉬운(아르바이트인 채에서도 「이름」을 그대로 읽을 수 있다)나름, 「이름」은URL encode에 걸리지 않는 영수의 문자열로 하는 것이 트러블 방지가 되겠지요.
그런데, 다음과 같이 이름과 값쌍방을Java 의URLEncoder 그리고 encode 해 만든 쿠키는 어떻게 브라우저가 처리할까 조사해 봅시다.
String namestring = " 내각총리대신";
String valuestring = " 코이즈미 쥰이치로";
namestring = URLEncoder.encode(namestring, "Shift_JIS");
valuestring = URLEncoder.encode(valuestring, "Shift_JIS");
cookie = new Cookie(namestring, valuestring);
그렇다면,c:windowscookies 의 파일을 조사해 보면 다음과 같이 브라우저는URL encode 된 문자열을 그대로 받고 있을 뿐이라고 말하는 것을 알 수 있습니다.이것을 바탕으로 되돌리는 것은 프로그래머의 책임이라고 하는 것입니다.
%93%E0%8A%74%91%8D%97%9D%91%E5%90%62
%8F%AC%90%F2%8F%83%88%EA%98%59
localhost/examples/servlet/
1024
3287822464
29522316
294622464
29522316
*
즉Netscape 의 생각은, 「쿠키는1 아르바이트 문자로, 한편 안전한 문자로 구성된 문자열이 이름과 값의 페어로서 존재하고 있는 것을 전제로 하고 있다.그렇지 않은 문자열을 그러한 제약에 따라서 변환해 사용하는 것은 프로그래머의 책임이다」 (이)라는 것이지요.
2. URL 인코딩이란
어떠한 아르바이트열에서도7 비트만의ASCII 문자를 사용해 인터넷의 그물을 통과시키기 위한 구조로서의URL 인코딩, 혹은 그 반대의URL 디코딩에 대해 좀 더 상세하게 이해하기로 하겠습니다.
메일(SMTP) (이)나HTTP 등의 패킷은, 헤더부에 행선지나 그 외 메세지의 제어에 관련되는 정보가 실립니다.이 헤더는 도중의(헤더가 해석된다) 게이트 웨이를 몇이나 중계되어 구석에서 구석의 노드에 전달되므로, 이러한 노드에 이해할 수 있는 코드와 문자로 표현되지 않으면 안됩니다.헤더부에 일본어와 같은2 아르바이트의 문자가 들어가면, 노드는 이것을1 아르바이트씩 해석하려고 합니다.그 때에 그 아르바이트의 어떤 것인가가 노드에 있어서 특별한 의미를 가지는 아르바이트이면, 올바른 결과를 얻을 수 없게 되어 버립니다.더욱 네트워크에 따라서는 각 바이트의 맨 위의 비트(MSB) (을)를 결핍 시키는 전송 노드가 존재합니다.따라서 어떠한 문자여도 그러한 제약 속에서 안전하게 한편 투과적으로 전송되는 것이 필요하게 됩니다.구체적으로는7 비트로 한편 「안전한」ASCII(American Standard Code for Information Interchange) 캐릭터 세트로부터 되는 문자열로 변환해 인터넷을 통하는 것입니다.그러한 구조로서URL encode를 생각할 수 있었습니다.URL encode라고 하는 것은, 원래 헤더부의URL 부분에2 아르바이트 문자나 제어 문자와 혼동하기 쉬운 문자가 들어가는 것을 방지하기 위해서 생각할 수 있었기 때문에 그렇게 불리고 있습니다.그러나 보내지는 정보를 모두 「보인다」문자열로 변환하는 것은 형편이 좋은 것이 많아, 메세지의 보디 부분의 전달에도 사용됩니다.보디 부분의 변환에는 또 하나MIME(Multi-Purpose Internet Mail Extensions) 의 인코딩이 있습니다.이것은2 아르바이트의 바이너리·데이터를3 아르바이트의7 비트ASCII 문자로 변환하는 것으로, 멀티미디어 정보의 전송에 사용됩니다.
URL encode의 순서는 이하같습니다.
① 일본어와 같이2 아르바이트의 문자는1 아르바이트마다 꺼내ASCII 문자로 간주해 이하의 변환을 실시한다.
② 이름과 값에 있는 「안전하지 않다」문자는"%xx" 그렇다고 하는 이스케이프 문자열로 변환한다."xx" (은)는 그 문자의ASCII 값을16 진표시한 것이다.「안전하지 않다」문자에는=, &, %, +(이)나 프린트 할 수 없는 문자,MSB (최상위비트)(이)가1 의 문자를 포함한다.
③ 모든ASCII 의 스페이스 문자를+ (으)로 변환한다.
④ 이름과 값을= (와)과& 그리고 이어 하나의 문자열로 한다.예를 들면name1=value1&name2=value2&name3=value3
이 문자열이POST 요구 메세지의 보디 부분, 혹은GET 요구의 쿠에리 문자열, 혹은 쿠키의 헤더행으로서는 째 붐비어집니다.
3. JavaScript 에 있어서의escape() (와)과unescape() 함수
드디어 클라이언트(브라우저) 쪽에 이야기를 옮깁시다.JavaScript 그럼 당초는escape() (와)과unescape() 의 글로벌 함수가 그러한 목적으로 사용되는 일이 있었습니다.그러나 이러한 함수는 완전한URL encode 대응이 아닌 데다가, 그 함수의 정의가 도중에 바뀌어 버려, 추천할 수 없습니다.
그렇다면JavaScript 그리고 쿠키를 읽어낼 때,URL encode 된 쿠키를 어느 캐릭터 세트라고 이해해 디코드하는 것입니까?Java 냄새나도URLEncoder (와)과URLDecoder 의 두 개의 클래스에 있어 캐릭터 세트(게다가W3C 하지만 권고하고 있다고UTF-8 (을)를 추천! )(을)를 지정하게 된 것이 최근의 일(j2sdk1.4 (으)로부터)입니다.
JavaScript 의 언어 사양(escape/unescape) 에는 그러한 기능이 존재하지 않는 것이 혼란의 토대가 되고 있는 것 같습니다.예를 들면escape() 메소드는NN(Netscape Navigator) 하Shift_JIS 의 코드를URL encode나무로,IE(Internet Explorer) (은)는 Unicode 표기(이스케이프·순서이며UTF (은)는 아니다!)(을)를 돌려주어 버립니다. 역조작의escape() 메소드도 이것에 대응합니다. 그런데 문제를 더욱 복잡하게 하고 있는 것이,IE 의escape() 함수는 통상의UTF-16의URL encode(예를 들면j2sdk1.4 의URLEncoder.encode(str, “UTF-16 ”); )(와)과는 완전히 다른 단순한 Unicode 표기의 문자열을 만들어 낸다, 라고 하는 것입니다. 예를 들면 다음과 같은htm 파일을IE 그리고 열리면,
<HTML>
<HEAD>
<TITLE>JavaScript escape()/unescape() functionarity test</TITLE>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=SHIFT_JIS">
</TITLE>
<BODY>
<PRE>
JavaScript 에 있어서의escape 함수의 브라우저에 의한 상위를 체크한다
<SCRIPT LANGUAGE="JavaScript">
s=" 내각총리대신= 코이즈미 쥰이치로";
document.writeln("original string : "+s);
s=escape(s);
document.writeln("escaped string : "+s);
s=unescape(s);
document.writeln("unescaped string : "+s);
</SCRIPT>
</PRE>
</BODY>
</HTML>
JavaScript 에 있어서의escape 함수의 브라우저에 의한 상위를 체크한다
original string : 내각총리대신= 코이즈미 쥰이치로
escaped string : %u5185%u95A3%u7DCF%u7406%u5927%u81E3%3D%u5C0F%u6CC9%u7D14%u4E00%u90CE
unescaped string : 내각총리대신= 코이즈미 쥰이치로
즉%uⅴⅴ 되는 Unicode의16 진표기를 돌려주고 있는 것이 분 빌려지요.
다음과 같이,IE 하지만unescape() 함수를 사용해 읽어낼 수 없을까URLEncoder.encode() 메소드를 사용해 서버측에서,cookie (을)를 세트 했다고 합시다.
import java.io.*;
import java.net.*;
import javax.servlet.*;
import javax.servlet.http.*;
/** 쿠키 읽고 쓰기 서브 렛 **/
public class HelloCookie extends HttpServlet {
public void doGet (HttpServletRequest req, HttpServletResponse res) throws ServletException, IOException {
PrintWriter out;
Cookie[] cookies;
Cookie cookie;
String urlencoding = "UTF-16"; // 필요하게 응해"Shift_JIS" (이)나 ”UTF-8 ” 등을 시험한다
// Cookie 의 취득
cookies = req.getCookies();
cookie = null;
if (cookies != null){
for(int i=0; i < cookies.length; i++) {
cookie = cookies[i];
if (cookie.getName().equals("HelloCookie")) { break; }
}
}
res.setContentType("text/html; charset=Shift_JIS");
out = res.getWriter();
if (cookie == null) { // Cookie 의 기재
String namestring = " 내각총리대신";
String valuestring = " 코이즈미 쥰이치로";
namestring = URLEncoder.encode(namestring, urlencoding);
valuestring = URLEncoder.encode(valuestring, urlencoding);
cookie = new Cookie(namestring, valuestring);
cookie.setMaxAge(300); // 유효기간은5 분에 끊어진다
res.addCookie(cookie);
out.println("<html><body>");
out.println("<h1>Write Cookie</h1>");
out.println("<P>");
out.println("<SCRIPT LANGUAGE="JavaScript">");
out.println("s=unescape(document.cookie);");
out.println("document.write("unescaped cookie : "+s);");
out.println("</SCRIPT>");
out.println("</P>");
out.println("<p> 리로드 해 주세요.</p>");
out.println("</body></html>");
} else { // Cookie 의 표시
out.println("<html><body>");
out.println("<h1>");
out.println(URLDecoder.decode(cookie.getValue(), urlencoding));
out.println("</h1>");
out.println("<p>Cookie 의 샘플(HelloCookie.java )</p>");
out.println("</body></html>");
}
}
}
이 때telnet 그리고 액세스 해Tomcat 하지만 송신한다HTTP 응답 패킷의Set-Cookie 행을 조사하면 다음과 같이 되어 있습니다.
Set-Cookie: %FE%FF%51%85%95%A3%7D%CF%74%06%59%27%81%E3=%FE%FF%5C%0F%6C%C9%7D
%14%4E%00%90%CE;Expires=Wed, 23-Oct-2002 04:33:23 GMT
즉 「내각총리대신」의 문자열은%FE%FF%51%85%95%A3%7D%CF%74%06%59%27%81%E3 에, 「코이즈미 쥰이치로」의 문자열은%FE%FF%5C%0F%6C%C9%7D%14%4E%00%90%CE 에 변환되고 있습니다.FEFF 되는 문자열은 이것이BOM (아르바이트순서 마크)(으)로, 빅 endian인 것을 의미합니다.이것이 정식의UTF-16 코드 표시입니다.「내각총리대신= 코이즈미 쥰이치로」라고 하는 문자열의 경우는 다음과 같이 변환됩니다.
%FE%FF%51%85%95%A3%7D%CF%74%06%59%27%81%E3%00%3D%5C%0F%6C%C9%7D%14%4E%00%90%CE
당연한 일이면서 이 서브 렛의 출력을IE 의 unescape() 함수는 올바르게 받아들이고는 주지 않습니다.
IE 하지만 만들어 내는 「내각총리대신= 코이즈미 쥰이치로」의 인코딩은 조금 전 나타내 보인 것처럼 단순한 Unicode 표기의
%u5185%u95A3%u7DCF%u7406%u5927%u81E3%3D%u5C0F%u6CC9%u7D14%u4E00%u90CE
에서 만나며, 이것과는 완전히 차이가 납니다.게다가 ”= ” 그렇다고 하는 문자는 Unicode 표시되지 말고 단순한%3D 그렇다고 한다ASCII 문자로서 처리되어 버리고 있습니다.어째서%u003D (으)로 하지 않는 것일까요.ECMA-262 에 준거했지만나름입니다만, 곤란한 것입니다. 따라서 「IE 의 경우는 수상한escape() (와)과unescape() 함수는 사용하지 않는 편이 좋다」라고 하는 것이 결론입니다.
덧붙여서 방금전의 서브 렛으로 String urlencoding = "Shift_JIS"; (이)라고 변경하고, 이것을NN 그리고 호출하면 다음과 같이 정상적으로 표시됩니다.
단NN 그럼Shift_JIS 의URL encode를 사용하고 있으면 문제가 없는가 하면 유감스럽지만 그렇지는 않습니다.예를 들면 「내각총리대신 코이즈미 쥰이치로」라고 사이에 반각 스페이스 문자가 들어가 있으면NN (은)는 「내각총리대신+ 코이즈미 쥰이치로」라고 플러스 기호로 바꾸어 있습니다 .이것은URL encode의 해석의 상위에 의하는 것으로,j2sdk1.4 그럼 스페이스는 ”+ ” 문자로 변환하는데,NN 의escape() 함수의 경우는 스페이스를%20 (으)로 변환합니다. 세세한 일입니다만j2sdk1.4 그럼 총이라고 통일해%nn 의 형식에서 변환하는데NN 의escape() 함수의 경우는 아르바이트로 고쳤을 때에 위험한 문자가 아니면 그대로1 아르바이트 문자로서 변환합니다.구체적으로" 내각총리대신 코이즈미 쥰이치로" 되는 문자열의 변환의 상위를 나타내면:
J2sdk1.4의URLEncoder.encode()
%93%E0%8A%74%91%8D%97%9D%91%E5%90%62
+%8F%AC%90%F2%8F%83%88%EA%98%59
NN 의JavaScript의escape()
%93%E0%8At%91%8D%97%9D%91%E5%90b
%20%8F%AC%90%F2%8F%83%88%EA%98Y
이상로부터JavaScript 의escape() (와)과unescape() 하IE (와)과NN 쌍방으로 문제가 있어,Web 어플리와 같이 서버/IE /NN 함께 문제 없고 정보교환 찌를 수 있으려고 하는 곳 등의 함수는 사용해야 하는 것이 아니다, 라고 결론 됩니다.
4. JavaScript 에 있어서의encodeURI,decodeURI ,encodeURIComponent,decodeURIComponent
버젼
대표적인 브라우저
비고
1.0
NN2.0 의 도중 ~
IE3.0
JavaScript 의 오리지날의 사양
1.1
NN3
IE3.02+JScript1.3 패치
Array object (이)나 이벤트등의 추가
1.2
NN4.0 ~ 4.05
IE4
Layer/DIV 기능, CSS 의 추가
1.3
NN4.06 ~
IE5.0 ~
unicode 등 주로 ECMA-262 대응
1.4
NN5( 개발 중지 )
catch/try 등의 예외 처리 등( ECMA-262대응 )
1.5
Mozilla5( NN6 )
IE6 ~
ECMA-262 3rd Edition
2.0
?
ECMA-262 4th Edition
encodeURI
원래의 문자열
IE6 의 출력
NN7 의 출력
내각총리대신 코이즈미 쥰이치로
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
%20%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
%20%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
내각총리대신X 코이즈미 쥰이치로
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
X%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
X%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
encodeURIComponent
원래의 문자열
IE6 의 출력
NN7 의 출력
내각총리대신 코이즈미 쥰이치로
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
%20%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
%20%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
내각총리대신X 코이즈미 쥰이치로
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
X%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
X%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
카테고리
문자
reserved character
, / ? : @ & = + $ ,
이스케이프 하지 않는 문자
알파벳, 10 진수자, - _ . ! ~ * ' ( )
스코아
#
따라서document.cookie 그리고 꺼낸 문자열을 그대로 되돌릴 때는decodeURI() (을)를 사용하게 됩니다.쿠키의 「값」이나 「이름」을 처리할 때는decodeURIComponent() 등을 사용한다고 하고 있습니다.이것은JavaScript 하지만 쿠키를(이름, 값)의 오브젝트의 집합이 아니고, 단순한 문자열로서 취해 급 샀기 때문에 생긴 문제입니다. 이것도 또 프로그래머에게 혼란을 주는 요인이 됩니다.머지않아 그처럼 개정되게 되겠지요.
덧붙여서:
” %E5%86%85%E9%96%A3%E7%B7%8F%E7%90%86%E5%A4%A7%E8%87%A3%20%E5%B0%8F%E6%B3%89%E7%B4%94%E4%B8%80%E9%83%8E ”
되는 문자열은,decodeURI() 도decodeURIComponent() 도 같다 ” 내각총리대신= 코이즈미 쥰이치로 ”(을)를 돌려주겠습니다.
그렇지만, 호환성의 문제가 있습니다.즉j2sdk1.4 의URLencoder.encode(String, ”UTF-8 ”) 하지만 이스케이프 하는 캐릭터 세트와encodeURI 의 이스케이프 하는 캐릭터 세트가 다릅니다.또한,j2sdk1.4 그리고URL encode 한 문자열이decodeURI 함수에서는 올바르게 읽어낼 수 없게 됩니다.
encodeURI 함수가 이스케이프 하지 않는 문자는 아래 표같았습니다.
카테고리
문자
reserved character
, / ? : @ & = + $ ,
이스케이프 하지 않는 문자
알파벳, 10 진수자, - _ . ! ~ * ' ( )
스코아
#
EncodeURIComponent 함수 쪽은 이스케이프 하지 않는 문자열에는 reserved character가 포함되지 않는 것이 다른 곳(중)입니다.
그렇지만,j2sdk1.4 의URLencoder.encode(String, ”UTF-8 ”) 하지만 이스케이프 하지 않는 문자는 아래 표와 같이 되어 있습니다.적자 한편 기울기 문자의 부분이 이스케이프 하지 않는 문자, 단 스페이스(SP) 하 ”+ ” 에 옮겨놓아 한편 그것은 이스케이프 하지 않는 문자입니다.
Char Decimal Hex Char Decimal Hex
NUL 0 0 SOH 1 1
STX 2 2 ETX 3 3
EOT 4 4 ENQ 5 5
ACK 6 6 BEL 7 7
BS 8 8 HT 9 9
NL 10 a VT 11 b
NP 12 c CR 13 d
SO 14 e SI 15 f
DLE 16 10 DC1 17 11
DC2 18 12 DC3 19 13
DC4 20 14 NAK 21 15
SYN 22 16 ETB 23 17
CAN 24 18 EM 25 19
SUB 26 1a ESC 27 1b
FS 28 1c GS 29 1d
RS 30 1e US 31 1f
SP 32 20 ! 33 21
" 34 22 # 35 23
$ 36 24 % 37 25
& 38 26 ' 39 27
( 40 28 ) 41 29
* 42 2a + 43 2b
, 44 2c - 45 2d
. 46 2e / 47 2f
0 48 30 1 49 31
2 50 32 3 51 33
4 52 34 5 53 35
6 54 36 7 55 37
8 56 38 9 57 39
: 58 3a ; 59 3b
< 60 3c = 61 3d
> 62 3e ? 63 3f
@ 64 40 A 65 41
B 66 42 C 67 43
D 68 44 E 69 45
F 70 46 G 71 47
H 72 48 I 73 49
J 74 4a K 75 4b
N 78 4e O 79 4f
P 80 50 Q 81 51
R 82 52 S 83 53
T 84 54 U 85 55
V 86 56 W 87 57
X 88 58 Y 89 59
Z 90 5a [ 91 5b
92 5c ] 93 5d
^ 94 5e _ 95 5f
` 96 60 a 97 61
b 98 62 c 99 63
d 100 64 e 101 65
f 102 66 g 103 67
h 104 68 i 105 69
j 106 6a k 107 6b
l 108 6c m 109 6d
n 110 6e o 111 6f
p 112 70 q 113 71
r 114 72 s 115 73
t 116 74 u 117 75
v 118 76 w 119 77
x 120 78 y 121 79
z 122 7a { 123 7b
| 124 7c } 125 7d
~ 126 7e DEL 127 7f
따라서 실험 서브 렛의 프로그램으로,
String namestring = "URL encode의 실험";
String valuestring = " !"#$%&'()*+"+'u002c'+"-./01289:;<=>?@ABCXYZ[]"+'u005e'+'u005f'+'u0060'+"abcxyz{|}"+'u007e';
namestring = URLEncoder.encode(namestring, urlencoding);
valuestring = URLEncoder.encode(valuestring, urlencoding);
(으)로서 'u0020 ' (으)로부터 'u007e ' 까지의 문자가 어떻게URL encode 되어 한편JavaScript 의decodeURI 함수가 어떻게 디코드할까를 시험해 보면 다음과 같은 결과를 얻을 수 있습니다.
undecoded cookie : URL%E3%82%A8%E3%83%B3%E3%82%B3%E3%83%BC%E3%83%89%E3%81%AE%E5%AE%9F%E9%A8%93
=+%21%22%23%24%25%26%27%28%29*%2B%2C-.%2F01289%3A%3B%3C%3D%3E%3F%40ABCXYZ%5B%5C%5D%5E_%60
abcxyz%7B%7C%7D%7E
decoded cookie : URL encode의 실험=+!"%23%24%%26'()*%2B%2C-.%2F01289%3A%3B<%3D>%3F%40ABCXYZ[]^_`abcxyz{|}~
즉decodeURI 함수는 reserved character와 스코아 문자에의 디코드는 하지 않고, 그대로 이스케이프 표시를 돌려주어 버리고 있습니다.실제는encodeURI 그리고 이스케이프 하지 않는 문자에의 디코드총이라고가 비디코드의 대상이 됩니다.
「이러한 문자를 사용하지 않는다」라고 하는 것도 하나의 해결법일지도 모르지만, 너무 좋은 수단이라고는 할 수 없습니다.
또, 쿠키를 일괄 encode 하는 경우는encodeURIComponent 함수를 이용해서는 안되는 것도 잊지 말아 주세요.
5. 그러면 도대체 어떻게 하면 좋은가?
현재 상태로서는 유감스럽지만encodeURI ,decodeURI ,encodeURIComponent,decodeURIComponent 그렇다고 하는 함수를 사용할 수 없는 브라우저가 아직도 많이 이용되고 있는 현상인 것, 이러한 함수가Java 2 플랫폼의URL encode와의 호환성이 없는 것을 감안하고,cookie (와)과JavaScript (을)를 사용해 클라이언트/서버간에 정보교환 하는 경우에는 어떻게 하면 좋은 것일까요?결국 다음과 같은 결론이 됩니다.
결론
JavaScript 하지만 서버가 세트 한 쿠키를 처리하는 어플리케이션에 대해:
1) 쿠키의 이름과 값 모두URL encode 하는 것이 추천 되지만, 이름은 「위험」이 아니다(URLencode에 영향을 받지 않는다) 문자로부터 되는 영수문자열에 한정해야 합니다 .telnet등의 툴에 의한 검증이나 디버그의 변을 배려한 것입니다.
2) NN 및IE 의escape() (와)과unescape() 함수는 문제가 있으므로 사용하고는 되지 않습니다.EncodeURI() ,decodeURI() ,encodeURIComponent() ,decodeURIComponent() 도, 낡은 버젼의 브라우저에서는 대응 되어 있지 않고,j2sdk1.4 (와)과의 호환성의 문제가 있습니다.결국J2sdk1.4 의java.net 의 패키지에 있다URLEncoder.encode()및URLDecoder.decode() (와)과 같은 기능을 가졌다JavaScript 의 함수를 준비하는 것이 베스트입니다. 그러면 자신이 어느 브라우저상의 어느 버젼으로 달리고 있을까를JavaScript (은)는 식별할 필요도 없어집니다.
URL encode는UTF-8 에 통일한다. 이것은EncodeURI() ,decodeURI() ,encodeURIComponent(),decodeURIComponent() 하지만UTF-8 (을)를 사용하고 있기 때문이라고 하는 이유입니다.또Java 의 사양에 대해도UTF-8 (을)를 추천 하고 있습니다.일본어에서는 지극히 효율이 나쁩니다만, 이 세계에서는UTF-8 (을)를 표준적으로 사용하는 편이 무난하겠지요.
6. UTF-8 의URL encode·디코드 함수의 예:
Unicode(1 아르바이트,2 아르바이트장,4 아르바이트장이 있다)를 외부와 아르바이트열로서 교환하는 형식(Unicode Transfer Format: UTF )에는UTF-8 (와)과UTF-16 하지만 잘 사용됩니다.이번은UTF-8 에 의한다URL encode를 검토하므로,UTF-8 에의URL 변환법을 소개합니다.이대로 사용할거라고는 말씀드리지 않습니다.이 프로그램을 참고로 해 주시면 다행입니다.
UCS (으)로부터UTF-8 에의 변환법은 다음의 테이블에 나타낸 것처럼 됩니다.
UCS (으)로부터UTF-8 에의 변환법
UCS-2 (UCS-4)
비트 패턴
제1바이트
제2바이트
제3바이트
제4바이트
U+0000 ..
U+007F
00000000-0xxxxxxx
0xxxxxxx
U+0080 ..
U+07FF
00000xxx-xxyyyyyy
110xxxxx
10yyyyyy
U+0800 ..
U+FFFF
xxxxyyyy-yyzzzzzz
1110xxxx
10yyyyyy
10zzzzzz
U+10000..
U+1FFFFF
00000000-000wwwxx-
xxxxyyyy-yyzzzzzzz
11110www
10xxxxxx
10yyyyyy
10zzzzzz
이 형식의 특징은1 아르바이트 문자 이외는 맨 위의 비트(MSB) 하지만 제로가 되지 않는 것으로, 맨 위의 비트가 제로의 문자는7 비트ASCII 캐릭터 세트 그 자체라고 하는 것입니다.따라서 변환의 알고리즘은 지극히 간단합니다.URL 변환에 즈음해서는1 아르바이트 형식 이외의 형식에서는 반드시 각 바이트는%hh (와)과 이스케이프 형식이 됩니다.
java.net.URLencoder.encode(String, ”UTF-8 ”) 에 상당한 함수를JavaScript 그리고 실현될 때는, 다음과 같은 알고리즘이 됩니다.
만약 그 문자가'u0020 '(이)라면, 그것을'u002b '에 옮겨놓는다
그렇지 않으면,
만약 그 문자가'u002a ','u002d ','u002e ','u0030 'ⅴ'u0039 ', 'u0042 'ⅴ
'u005a ','u005f ','u0061 'ⅴ'u007a '(이)가 아니면
그 문자를UTF-8 변환해, 각 바이트를%XX 의 이스케이프 문자열로 변환한다
java.net.URLdecoder.decode(String, ”UTF-8 ”) 에 상당한 함수의 알고리즘은;
만약 그 문자가'+ '(이)라면, 그것을' '에 옮겨놓는다
그 이외의 문자로,
만약 그 문자가 이스케이프 문자열이라면 이것을UTF-8 변환이라고 해 Unicode 문자에 되돌린다
(그 이외의 문자는 그대로)
(와)과 간단한 것입니다.
이하에 그 함수와 실험용HTML (을)를 나타냅니다.이러한 함수는 장래의 확장4 아르바이트장 Unicode(UCS-4) 에도 대응하고 있습니다.이HTML 파일을 브라우저로 열리면 다음과 같은 결과를 얻을 수 있겠지요.
JavaScript 에 의한다J2 플랫폼 호환URL encode 함수와 그 테스트
original string : 내각총리대신 코이즈미 쥰이치로 !"#$%&'()*+,-./01289:;<=>?@ABCXYZ[]^_`abcxyz{|}~
URL encoded string : %e5%86%85%e9%96%a3%e7%b7%8f%e7%90%86%e5%a4%a7%e8%87%a3+%e5%b0%8f%e6%b3%89%e7%b4%94%e4%b8%80%e9
%83%8e+%21%22%23%24%25%26%27%28%29*%2b%2c-.%2f01289%3a%3b%3c%3d%3e%3f%40ABCXYZ%5b%5c%5d%5e_%60
abcxyz%7b%7c%7d%7e
URL decoded string : 내각총리대신 코이즈미 쥰이치로 !"#$%&'()*+,-./01289:;<=>?@ABCXYZ[]^_`abcxyz{|}~
실제의 어플리케이션에 대해:
아) 웹·서버측은 「값」의 문자열을java.net.URLEncoder.encode(String, “UTF-8 ”) (을)를 사용해URL encode 해 쿠키의 「값」에 세트 한다
이) 브라우저는Window.document.cookie 그리고 꺼낸 문자열을
( 아) 「이름」과「값」에 위험한 문자가 포함되지 않으면 그대로 새롭다decodeURL() 에 걸치는지,
( 이) 「값」의 문자열을decodeURL() 에 걸칠까
해 올바른 문자열에 되돌리게 됩니다.
우) Window.document.cookie (을)를 변경하는 경우는, 새롭다encodeURL() 함수를 사용해 반대의 조작을 합니다.단Window.document.cookie 에 무엇인가 새로운 「이름」의 문자열을 대입하는 것은, 지금까지의 쿠키에 새로운 쿠키가 추가된다( 「이름」이 같으면 그 「값」을 고쳐 쓸 수 있습니다.) 되는 것 에 주의합시다.
참고:
쿠키중에서 소정의 이름의 값을 추출하는 함수의 예입니다.
function loadCookie(name) {
var allcookies = document.cookie;
if (allcookies == "") return "";
var start = allcookies.indexOf(name + "=");
if (start == -1) return "";
start += name.length + 1;
var end = allcookies.indexOf(';',start);
if (end == -1) end = allcookies.length;
return allcookies.substring(start,end);
}
쿠키의 「값」이URL encode 되고 있는 경우는,
var decodedValue = decodeURL("loadCookie(name);
(와)과 같이 디코드합니다.또 「이름」이나 「값」에 예약어(reserved word)가 포함되지 않은 것이 뚜렷한 경우는
var allcookies = decodeURL("document.cookie);
그렇다고 하는 일괄처리의 사용법도 가능합니다.
프로그램예
<HTML>
<HEAD>
<TITLE>j2 platform equivalent URL encode/decode functions</TITLE>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=SHIFT_JIS">
</TITLE>
<SCRIPT LANGUAGE="JavaScript">
/* Function Equivalent to java.net.URLEncoder.encode(String, "UTF-8")
Copyright (C) 2002, Cresc Corp.
Version: 1.0
*/
function encodeURL("str){
var s0, i, s, u;
s0 = ""; // encoded str
for (i = 0; i < str.length; i++){ // scan the source
s = str.charAt(i);
u = str.charCodeAt(i); // get unicode of the char
if (s == " "){s0 += "+";} // SP should be converted to "+"
else {
if ( u == 0x2a || u == 0x2d || u == 0x2e || u == 0x5f || ((u >= 0x30) && (u <= 0x39)) || ((u >= 0x41) && (u <= 0x5a)) || ((u >= 0x61) && (u <= 0x7a))){ // check for escape
s0 = s0 + s; // don't escape
}
else { // escape
if ((u >= 0x0) && (u <= 0x7f)){ // single byte format
s = "0"+u.toString(16);
s0 += "%"+ s.substr(s.length-2);
}
else if (u > 0x1fffff){ // quaternary byte format (extended)
s0 += "%" + (oxf0 + ((u & 0x1c0000) >> 18)).toString(16);
s0 += "%" + (0x80 + ((u & 0x3f000) >> 12)).toString(16);
s0 += "%" + (0x80 + ((u & 0xfc0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
else if (u > 0x7ff){ // triple byte format
s0 += "%" + (0xe0 + ((u & 0xf000) >> 12)).toString(16);
s0 += "%" + (0x80 + ((u & 0xfc0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
else { // double byte format
s0 += "%" + (0xc0 + ((u & 0x7c0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
}
}
}
return s0;
}
/* Function Equivalent to java.net.URLDecoder.decode(String, "UTF-8")
Copyright (C) 2002, Cresc Corp.
Version: 1.0
*/
function decodeURL("str){
var s0, i, j, s, ss, u, n, f;
s0 = ""; // decoded str
for (i = 0; i < str.length; i++){ // scan the source str
s = str.charAt(i);
if (s == "+"){s0 += " ";} // "+" should be changed to SP
else {
if (s != "%"){s0 += s;} // add an unescaped char
else{ // escape sequence decoding
u = 0; // unicode of the character
f = 1; // escape flag, zero means end of this sequence
while (true) {
ss = ""; // local str to parse as int
for (j = 0; j < 2; j++ ) { // get two maximum hex characters for parse
sss = str.charAt(++i);
if (((sss >= "0") && (sss <= "9")) || ((sss >= "a") && (sss <= "f")) || ((sss >= "A") && (sss <= "F"))) {
ss += sss; // if hex, add the hex character
} else {--i; break;} // not a hex char., exit the loop
}
n = parseInt(ss, 16); // parse the hex str as byte
if (n <= 0x7f){u = n; f = 1;} // single byte format
if ((n >= 0xc0) && (n <= 0xdf)){u = n & 0x1f; f = 2;} // double byte format
if ((n >= 0xe0) && (n <= 0xef)){u = n & 0x0f; f = 3;} // triple byte format
if ((n >= 0xf0) && (n <= 0xf7)){u = n & 0x07; f = 4;} // quaternary byte format (extended)
if ((n >= 0x80) && (n <= 0xbf)){u = (u << 6) + (n & 0x3f); --f;} // not a first, shift and add 6 lower bits
if (f <= 1){break;} // end of the utf byte sequence
if (str.charAt(i + 1) == "%"){ i++ ;} // test for the next shift byte
else {break;} // abnormal, format error
}
s0 += String.fromCharCode(u); // add the escaped character
}
}
}
return s0;
}
</SCRIPT>
</HEAD>
<BODY>
<PRE>
JavaScript 에 의한다J2 플랫폼 호환URL encode 함수와 그 테스트
<SCRIPT LANGUAGE="JavaScript">
s = " 내각총리대신 코이즈미 쥰이치로" + " !"#$%&'()*+" + 'u002c'+ "-./01289:;<=>?@ABCXYZ[]" + 'u005e' + 'u005f' + 'u0060' + "abcxyz{|}" + 'u007e';
document.writeln("original string : "+s);
s = encodeURL("s);
document.writeln("URL encoded string : "+s);
s = decodeURL("s);
document.writeln("URL decoded string : "+s);
</SCRIPT>
</PRE>
</BODY>
</HTML>
7. JSP (와)과JavaScript 사이의 쿠키에 의한 데이터 교환예
마지막에 여러분이 실제로 서버의 프로그램이 작성될 때의 참고로서JSP (와)과JavaScript 사이에 텍스트를 쿠키를 개입시켜 교환하는 샘플을 나타내 보이겠습니다.
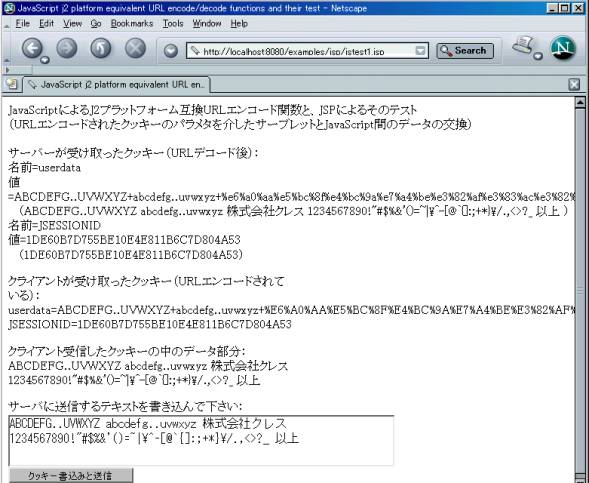
이JSP (을)를 브라우저가 액세스 하면 다음과 같은 화면을 얻을 수 있을 것입니다.
동작은 다음과 같습니다:
1. 최초로 유저는 텍스트 에리어에 임의의 텍스트를 입력해, 「쿠키 기재와 송신」의 버튼을 누르면, 그 텍스트는URL encode 된 후 ”userdata ” 그렇다고 하는 「이름」의 「값」으로 해서 쿠키에 세트 되어 서버에 보내집니다.
2. 서버는 클라이언트로부터 보내져 온 쿠키의 내용의 모든 것을 먼저 「이름」/「값」세트로서 클라이언트에의HTML 텍스트에 씁니다.그 때 「값」 쪽은URL 디코드한 것을 괄호로 묶어 함께 씁니다.
3. 서버는 ”userdata ” 그렇다고 하는 「이름」의 「값」의 부분을URL 디코드한 유저로부터의 텍스트를 재차URL encode 해 쿠키에 세트 합니다.
4. 클라이언트 쪽은, 서버로부터의HTML 텍스트를 표시 함과 동시에, 함께 보내져 왔다JavaScript에 의해 수신한 쿠키의 내용을 생으로 표시해, 다음에 ”userdata ” 의 「값」의 부분을URL 디코드해 표시합니다.
5. 송신한 텍스트와 돌려 보내져 온 텍스트가 일치하면, 올바르게 교신을 할 수 있던 것이 됩니다.
정말로 쿠키가 서버와 클라이언트 쌍방에서 쓰고 있을까 걱정입니까?URL encode 된 쿠키의 「값」을 봐 주세요.이스케이프 된 문자가JavaScript 쪽은 소문자의16 진표시,JSP 쪽은 대문자의16 진표시가 되어 있습니다.이것은JavaScript 의Number.toString(16) 메소드가 소문자로 출력하는데 대해,Java 2 플랫폼의URLEncoder.encode(String, ”UTF-8 ”) 되는 메소드는 대문자로 출력하기 때문입니다.이것으로 쌍방의URL 처리 함수가 기능해, 한편 호환성을 잡히고 있는 것이 확인됩니다.
덧붙여 복귀나 개행도 입력할 수 있기 때문에 시험해 주세요.HTML 그럼 이러한 문자는 표시되지 않습니다만, 올바르고 encode 처리되고 있는 것을 알 수 있습니다.브라우저의 설정에 따라서는 복귀(CR: %0d) (와)과 개행(NL: %0a) 쌍방이 쿠키에 들어가는 경우도 있고, 개행만의 경우도 있기 때문에 개행 처리에는 주의가 필요합니다.
이하에JSP 페이지를 소개합니다.JSP 속에JavaScript 도 들어가 있으므로 읽기 어려운 곳은 참아 주세요.JSP 의 프로그램 부분을 빨강으로,JavaScript 의 부분을 파랑으로 분류 되어 있습니다.이 프로그램을 실제로 체험한 후, 읽어 받는다고 이해가 빠르다고 생각합니다.
<%@ page contentType="text/html; charset=Shift_JIS" session="true"
import="java.net.*" %>
<% Cookie[] cookies;
Cookie cookie;
cookies = request.getCookies();
cookie = null;
if (cookies != null){
for (int i = 0; i < cookies.length; i++){
cookie = cookies[i];
if (cookie.getName().equals("userdata")){break;}
}
String encodedUserData = cookie.getValue();
String decodedUserData = URLDecoder.decode(encodedUserData, "UTF-8");
cookie = new Cookie("userdata", URLEncoder.encode(decodedUserData, "UTF-8"));
cookie.setMaxAge(300); // give 5 minute to survive for the cookie
response.addCookie(cookie);
}
%>
<HTML>
<HEAD>
<TITLE>JavaScript j2 platform equivalent URL encode/decode functions and their test</TITLE>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=SHIFT_JIS">
</TITLE>
<SCRIPT LANGUAGE="JavaScript">
/* Function Equivalent to URLEncoder.encode(String, "UTF-8")
Copyright (C) 2002 Cresc Corp.
Version: 1.0
*/
function encodeURL("str){
var s0, i, s, u;
s0 = ""; // encoded str
for (i = 0; i < str.length; i++){ // scan the source
s = str.charAt(i);
u = str.charCodeAt(i); // get unicode of the char
if (s == " "){s0 += "+";} // SP should be converted to "+"
else {
if ( u == 0x2a || u == 0x2d || u == 0x2e || u == 0x5f || ((u >= 0x30) && (u <= 0x39)) || ((u >= 0x41) && (u <= 0x5a)) || ((u >= 0x61) && (u <= 0x7a))){ // check for escape
s0 = s0 + s; // don't escape
}
else { // escape
if ((u >= 0x0) && (u <= 0x7f)){ // single byte format
s = "0"+u.toString(16);
s0 += "%"+ s.substr(s.length-2);
}
else if (u > 0x1fffff){ // quaternary byte format (extended)
s0 += "%" + (oxf0 + ((u & 0x1c0000) >> 18)).toString(16);
s0 += "%" + (0x80 + ((u & 0x3f000) >> 12)).toString(16);
s0 += "%" + (0x80 + ((u & 0xfc0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
else if (u > 0x7ff){ // triple byte format
s0 += "%" + (0xe0 + ((u & 0xf000) >> 12)).toString(16);
s0 += "%" + (0x80 + ((u & 0xfc0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
else { // double byte format
s0 += "%" + (0xc0 + ((u & 0x7c0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
}
}
}
return s0;
}
/* Function Equivalent to URLDecoder.decode(String, "UTF-8")
Copyright (C) 2002 Cresc Corp.
Version: 1.0
*/
function decodeURL("str){
var s0, i, j, s, ss, u, n, f;
s0 = ""; // decoded str
for (i = 0; i < str.length; i++){ // scan the source str
s = str.charAt(i);
if (s == "+"){s0 += " ";} // "+" should be changed to SP
else {
if (s != "%"){s0 += s;} // add an unescaped char
else{ // escape sequence decoding
u = 0; // unicode of the character
f = 1; // escape flag, zero means end of this sequence
while (true) {
ss = ""; // local str to parse as int
for (j = 0; j < 2; j++ ) { // get two maximum hex characters to parse
sss = str.charAt(++i);
if (((sss >= "0") && (sss <= "9")) || ((sss >= "a") && (sss <= "f")) || ((sss >= "A") && (sss <= "F"))) {
ss += sss; // if hex, add the hex character
} else {--i; break;} // not a hex char., exit the loop
}
n = parseInt(ss, 16); // parse the hex str as byte
if (n <= 0x7f){u = n; f = 1;} // single byte format
if ((n >= 0xc0) && (n <= 0xdf)){u = n & 0x1f; f = 2;} // double byte format
if ((n >= 0xe0) && (n <= 0xef)){u = n & 0x0f; f = 3;} // triple byte format
if ((n >= 0xf0) && (n <= 0xf7)){u = n & 0x07; f = 4;} // quaternary byte format (extended)
if ((n >= 0x80) && (n <= 0xbf)){u = (u << 6) + (n & 0x3f); --f;} // not a first, shift and add 6 lower bits
if (f <= 1){break;} // end of the utf byte sequence
if (str.charAt(i + 1) == "%"){ i++ ;} // test for the next shift byte
else {break;} // abnormal, format error
}
s0 += String.fromCharCode(u); // add the escaped character
}
}
}
return s0;
}
/* Function to get cookie parameter value string with specified name
Copyright (C) 2002 Cresc Corp.
Version: 1.0
*/
function loadCookie(name) {
var allcookies = document.cookie;
if (allcookies == "") return "";
var start = allcookies.indexOf(name + "=");
if (start == -1) return "";
start += name.length + 1;
var end = allcookies.indexOf(';',start);
if (end == -1) end = allcookies.length;
return decodeURL("allcookies.substring(start,end);
}
/* Function to send the textarea data throuth cookie
Copyright (C) 2002 Cresc Corp.
Version: 1.0
*/
function sendThis(){
document.cookie="userdata="+encodeURL("document.inForm.text.value); //set data
window.location.reload(); // and reload this page
}
</SCRIPT>
</HEAD>
<BODY>
JavaScript 에 의한다J2 플랫폼 호환URL encode 함수와JSP 에 의한 그 테스트<BR>
(URL encode 된 쿠키의 파라미터를 개입시킨 서브 렛과JavaScript 사이의 데이터의 교환)<BR><BR>
<% if (cookies != null){ %>
<DIV STYLE="width: 50% word-break:break-all">
서버가 받은 쿠키(URL 디코드 후):<BR><%
for (int i = 0; i < cookies.length; i++){ %>
이름=<%= cookies[i].getName() %><BR>
치=<%= cookies[i].getValue() %><BR>
(<%= URLDecoder.decode(cookies[i].getValue(), "UTF-8") %>)<BR>
<% }
} %>
</DIV>
<P STYLE="width: 50%">
클라이언트가 받은 쿠키(URL encode 되고 있다):<BR>
<SCRIPT LANGUAGE="JavaScript">
document.writeln(document.cookie);
</SCRIPT>
</P>
<P STYLE="width: 50%">
클라이언트 수신한 쿠키안의 데이터 부분:<BR>
<SCRIPT LANGUAGE="JavaScript">
document.writeln(loadCookie("userdata"));
</SCRIPT>
</P>
서버에 송신하는 텍스트를 써 주세요:<BR>
<FORM NAME="inForm">
<TEXTAREA ROWS="3" COLS="60" WRAP="soft" NAME="text"></TEXTAREA><BR>
<INPUT TYPE="button" VALUE=" 쿠키 기재와 송신" ONCLICK="sendThis()">
</FORM>
</BODY>
</HTML>
[출처] JavaScript 에 있어서의URL encode의 처리|작성자 JULIAN
2. 원문
JavaScriptにおけるURLエンコ?ドの?理
このメモは、JavaScriptでクッキ?を?理する場合のポイントをお示しし、URLエンコ?ドに?わるトラブルを回避していただくことを目的にしています。お急ぎの方は3章と4章を飛ばして?んで頂いて構いません。なおこのメモはなるべくIEでご?下さい。
目次
3. 3 JavaScriptにおけるescape()とunescape()??
4. 4 JavaScriptにおけるencodeURI、decodeURI、encodeURIComponent、decodeURIComponent
HTMLテキスト以外にウェブ?サ?バがブラウザに情報を渡す手段は、HTTP?答メッセ?ジのヘッダ部分にその情報をセットすることです(ボディ部分には通常HTMLテキストが入ります)。サ?バ側からはクッキ?設定のヘッダ行や自分で作った特別なヘッダ行に情報をセットできます。これらは(名前、値)のペアの形式をとります。
HTMLテキスト外で渡される情報は、ブラウザ?面に表示されないので、表示の目的以外のセッション管理などに使われます。サ?ブレットにおけるクッキ?によるセッション維持のメカニズムは、まさしくこの特性を利用したものです。セッション以外にもクライアントとの各種管理情報(ブラウザのタイプやバ?ジョン、ユ?ザ情報など)、暗?化のための情報(鍵や方式など)の交信といった?用も考えられます。また送ったクッキ?はクライアントに蓄積されるので、繰り返し表示や?面に共通の情報を最初にクッキ?で送ってしまうことも可能です。また、フォ?ムに表示しないで必要な情報をサ?バに返すことも出?ます。
たとえばTomcatなどのサ?ブレット?エンジンがセッション維持に使っている(“jsessionid”, ID)の類のメカニズム以外に、もっと詳細にそのセッションの情報(ユ?ザの名前など)をクライアントで維持し、必要に?じこれを表示するなどが可能になります。
JavaScriptにおいては、HTTP?答メッセ?ジのヘッダ行を直接取り出す機能は?念ながらありません。しかしながらWindow.document.cookieオブジェクトを使って、クッキ?を介した情報のやり取りが可能です。しかしながら、後述のようにHTTPメッセ?ジのヘッダ行はURLエンコ?ドされねばなりません。ASCII文字セットだけで?む?米と違って我?のように2バイトの文字セットを標準的に使う場合は、URLエンコ?ドに注意しなければなりません。皆さんが?みまた問題を起こしやすいのはこの点でしょう。
このメモは、JavaScriptでクッキ?を?理する場合のポイントをお示しし、URLエンコ?ドに?わるトラブルを回避していただくことを目的にしています。
1. クッキ?とURLエンコ?ディング
クッキ?とURLエンコ?ディングの基本的な知識が必要になりますので、最初にそのポイントを?例でお示しします。
通常cookieはアプリケ?ション?サ?バがHTTP?答のパケットのヘッダ部分にセットしてブラウザに渡します。例えばIBMのサ?ブレット?エンジンは次のようなHTTPのヘッダ行をHTTP?答につけてセッション(サ?ビスとクライアントとの??の識別)の維持をとろうとしています。この例()ではsessionidという「名前」の??とLV??なる「値」の組を渡しています。
Set-Cookie: sessionid=LV140HYAAAABZQ....;Path=/
このようにcookieはHTTPパケットのヘッダ行によって?達されるので、2バイト文字や”;”や”=”などの危?な(プロトコル上意味を持つ)文字を含む「名前」や「値」を持つcookieをクライアントに渡すときは、危?なバイト文字を含まないようURLエンコ?ドして、バイト列として?達せねばなりません。
マルチバイト文字をサ?ブレット?エンジンは果たしてこれを認識して自動的にURLエンコ?ドしてくれるのだろうか??してみましょう。
次のサ?ブレットはネット上(http://ash.jp/java/hellocookie.htm)で公開されていたプログラムに一部手を加えたものです。このプログラムはサ?ブレットにおけるクッキ??理に?するヒントが入っていますので、ひととおり理解してください。
import java.io.*;
import java.net.*;
import javax.servlet.*;
import javax.servlet.http.*;
/** クッキ??み書きサ?ブレット **/
public class HelloCookie0 extends HttpServlet {
public void doGet (HttpServletRequest req, HttpServletResponse res) throws ServletException, IOException {
PrintWriter out;
Cookie[] cookies;
Cookie cookie;
// Cookieの取得
cookies = req.getCookies();
cookie = null;
if (cookies != null){
for(int i=0; i < cookies.length; i++) {
cookie = cookies[i];
if (cookie.getName().equals("HelloCookie")) { break; }
}
}
res.setContentType("text/html; charset=Shift_JIS");
out = res.getWriter();
HttpSession session = req.getSession(); // Sessionの取得と書き?み
session.setMaxInactiveInterval(600); // 10分間有?
if (session.isNew()) { // Cookieの書?み
cookie = new Cookie("HelloCookie", "Hello World!");
cookie.setMaxAge(60); // 有?期間は1分で切れる
res.addCookie(cookie);
out.println("<html><body>");
out.println("<h1>Write Cookie</h1>");
out.println("<p>リロ?ドしてください。</p>");
out.println("</body></html>");
} else { // Cookieの表示
out.println("<html><body>");
out.println("<h1>");
for(int i=0; i < cookies.length; i++) {
cookie = cookies[i];
out.println(cookie.getName()+" : "+ new String(cookie.getValue().getBytes("8859_1"), "Shift_JIS"));
out.println("<BR>");
}
out.println("</h1>");
out.println("<p>Cookieのサンプル(HelloCookie0.java)</p>");
out.println("</body></html>");
}
}
}
このプログラムでcookie = new Cookie("HelloCookie", "Hello World!");という行の「値」の文字列に漢字や危?な文字を設定するとサ?ブレット?エンジンはどのような?答パケットを送信するか試してみましょう。
a) ”Hello 日本!”と?えてtelnetのソフトウエアでアクセスすると次のような結果が得られます。最初の2行(空白行も含む)はtelnetが送ったHTTP要求メッセ?ジです。それ以降がサ?ブレット?エンジン(ここではTomcat)が返したHTTP?答メッセ?ジです。前半がヘッダ部分、最後の4行がボディ部分です。さてHTTP?答のヘッダ部分を見ると、Set-Cookieなるヘッダ行が2行存在することがお分かりでしょう。最初はサ?ブレットが作成したもので、後のはサ?ブレット?エンジンがセッション維持の?に作成したものです。?って、ブラウザにしてみると、2つのクッキ?が渡されたということになります。ブラウザ側でこれらのクッキ?に何も?更を加えなければ、サブミット?ボタンなどでこのURLを再度アクセスしたときには、これらのクッキ?は有?期限が切れていなければそのままサ?バに返されます。
GET /examples/servlet/HelloCookie0 HTTP/1.0
HTTP/1.1 200 OK
Content-Type: text/html; charset=Shift_JIS
Connection: close
Date: Wed, 30 Oct 2002 03:45:24 GMT
Server: Apache Tomcat/4.0.4-b3 (HTTP/1.1 Connector)
Set-Cookie: HelloCookie=Hello 日本!;Expires=Wed, 30-Oct-2002 03:50:25 GMT
Set-Cookie: JSESSIONID=BAFB93DD6C7848751C369747B316DB6C;Path=/examples
<html><body>
<h1>Write Cookie</h1>
<p>リロ?ドしてください。</p>
</body></html>
b) さてこのHTTP?答メッセ?ジをみると、telnetの??文字セットをShift_JISとしたので、“Hello 日本!”の部分は文字化けを起こさないで正しく?み出されています。また、IE(v6)でhttp://localhost:8080/examples/servlet/HelloCookie0とアクセスし、皆さんのPCのC:WINDOWSCookiesを調べると、このクッキ?が文字化けしないで受理されているのが確認できるでしょう。でも、?はこれは、たまたまうまくいったというだけなのです。”日本”という文字はShift_JISとしてヘッダに入っているのですが、このバイト列のどのバイトもASCIIの「危?な文字」に落ちていないからです。更に、この??ではロ?カルのホストを使っており、ネットワ?クを介してはいません。ネットワ?クのノ?ドによっては(古いシステムですが)7ビットしか?送されず、最上位の1ビット(MSB)は誤り?出や同期などの目的に使われているものもあります。そのようなノ?ドをこのHTTPメッセ?ジが通過すると、?然文字化けを生じてしまいます。
c) 危?な文字を含む文字列がクッキ?の「値」の場所にセットされたらどうなるでしょうか?クッキ?の「名前」に危?な1バイト文字が含まれているとサ?ブレット?エンジンは例外を生じるよう規定されているのですが、「値」にはそのような制約がどういう?だか規定されていません。試しに” AAA ;B%BB”とスペ?スとセミコロンを含む文字を出力してみよう。telnetでこのサ?ブレットを呼び出して見ると次のようなHTTP?答パケットを?察することができます。
HTTP/1.1 200 OK
Content-Type: text/html; charset=Shift_JIS
Connection: close
Date: Tue, 22 Oct 2002 04:39:25 GMT
Server: Apache Tomcat/4.0.4-b3 (HTTP/1.1 Connector)
Set-Cookie: HelloCookie=Hello AAA;B%BB;Expires=Tue, 22-Oct-2002 04:44:26 GMT
以下省略
これをブラウザ(IE6)はどのように取り?んだかをExplorerで見るとC:WINDOWSCookiesのディレクトリに記?されているファイルは次のようなテキストになっています。つまりスペ?スは受け付けたがセミコロン以降はクッキ?としては受け付けてはいないのです。セミコロンはインタ?ネットの世界では「?切り文字」なのです。
HelloCookie
AAA
localhost/examples/servlet/
1024
1088345728
29522332
2383813024
29522331
*
次の章で詳しく?明しますが、URLエンコ?ディングはMSBが1のバイトや、インタ?ネット上で特別の意味を持つ7ビットASCII文字を、7ビットASCII文字を使って混?させないで送るための仕組みなのです。
これまでの??からお分かりのように、クッキ?の送信にあたっては名前、値ともURLエンコ?ドして送ることが推?されます。これはNetScape社の解?書でも推?されていることであります。なおサ?ブレット?エンジンがセッション維持の?にcookieをセットするときはURLエンコ?ドしてはいない、というかURLエンコ?ドの必要のない文字しか使っていません(URL?換しても何の?化も生じません)。telnetなどで?査しやすい(バイトのままでも「名前」がそのまま?める)よう、「名前」はURLエンコ?ドに引っかからない英?の文字列にすることがトラブル防止になるでしょう。
さて、次のように名前と値?方をJavaのURLEncoderでエンコ?ドして作ったクッキ?はどのようにブラウザが?理するか調べてみましょう。
String namestring = "?閣?理大臣";
String valuestring = "小泉純一?";
namestring = URLEncoder.encode(namestring, "Shift_JIS");
valuestring = URLEncoder.encode(valuestring, "Shift_JIS");
cookie = new Cookie(namestring, valuestring);
そうすると、c:windowscookiesのファイルを調べてみると次のようにブラウザはURLエンコ?ドされた文字列をそのまま受け取っているだけだと言うことがわかります。これを元に?すのはプログラマの責任という?です。
%93%E0%8A%74%91%8D%97%9D%91%E5%90%62
%8F%AC%90%F2%8F%83%88%EA%98%59
localhost/examples/servlet/
1024
3287822464
29522316
294622464
29522316
*
つまりNetscapeの考え方は、「クッキ?は1バイト文字で、且つ安全な文字で構成された文字列が名前と値のペアとして存在していることを前提としている。そうでない文字列をそのような制約にしたがって?換して使うのはプログラマの責任である」というものでしょう。
2. URLエンコ?ディングとは
どのようなバイト列でも7ビットだけのASCII文字を使ってインタ?ネットの網を通過させるための仕組みとしてのURLエンコ?ディング、あるいはその逆のURLデコ?ディングについてもう少し詳細に理解することにします。
メ?ル(SMTP)やHTTPなどのパケットは、ヘッダ部に宛先やその他メッセ?ジの制御に?わる情報が載せられます。このヘッダは途中の(ヘッダが解?される)ゲ?トウエ?を幾つか中?され、端から端のノ?ドに?達されるので、これらのノ?ドに理解できるコ?ドと文字で表現されなければなりません。ヘッダ部に日本語のような2バイトの文字が入ると、ノ?ドはこれを1バイトずつ解?しようとします。そのときにそのバイトのどれかがノ?ドにとって特別の意味を持つバイトであったら、正しい結果が得られなくなってしまいます。更にネットワ?クによっては各バイトの一番上のビット(MSB)を欠落させる?送ノ?ドが存在します。?ってどのような文字であってもそのような制約のなかで安全に且つ透過的に?送されることが必要になります。具?的には7ビットで且つ「安全な」ASCII(American Standard Code for Information Interchange)文字セットからなる文字列に?換してインタ?ネットを通すということです。そのような仕組みとしてURLエンコ?ドが考えられました。URLエンコ?ドというのは、もともとヘッダ部のURL部分に2バイト文字や制御文字と紛らわしい文字が入るのを防止するために考えられたからそう呼ばれています。しかし送られる情報をすべて「見える」文字列に?換するのは都合が良いことが多く、メッセ?ジのボディ部分の?達にも使われます。ボディ部分の?換にはもうひとつMIME(Multi-Purpose Internet Mail Extensions)のエンコ?ディングがあります。これは2バイトのバイナリ?デ?タを3バイトの7ビットASCII文字に?換するもので、マルチメディア情報の?送に使われます。
URLエンコ?ドの手順は以下のようです。
① 日本語のように2バイトの文字は1バイト?にとりだしてASCII文字とみなして以下の?換を行う。
② 名前と値にある「安全でない」文字は"%xx"というエスケ?プ文字列に?換する。"xx"はその文字のASCII値を16進表示したものである。「安全でない」文字には=, &, %, +やプリントできない文字,MSB(最上位ビット)が1の文字を含む。
③ 全てのASCIIのスペ?ス文字を+に?換する。
④ 名前と値を=と&でつないでひとつの文字列にする。例えばname1=value1&name2=value2&name3=value3
この文字列がPOST要求メッセ?ジのボディ部分、あるいはGET要求のクエリ文字列、あるいはクッキ?のヘッダ行としてはめ?まれるのです。
3. JavaScriptにおけるescape()とunescape()??
いよいよクライアント(ブラウザ)のほうに話を移しましょう。JavaScriptでは?初はescape()とunescape()のグロ?バル??がそのような目的で使われることがありました。しかしこれらの??は完全なURLエンコ?ド??でない上に、その??の定義が途中で?わってしまい、お?めできません。
そうするとJavaScriptでクッキ?を?み出すとき、URLエンコ?ドされたクッキ?をどの文字セットだと理解してデコ?ドするのでしょうか?JavaにおいてもURLEncoderとURLDecoderの二つのクラスにおいて文字セット(しかもW3Cが?告しているからといってUTF-8を推?!)を指定するようになったのが最近のこと(j2sdk1.4から)なのです。
JavaScriptの言語仕?(escape/unescape)にはそのような機能が存在しないのが混?のもとになっているようです。例えばescape()メソッドはNN(Netscape Navigator)はShift_JISのコ?ドをURLエンコ?ドもどきで、IE(Internet Explorer)はユニコ?ド表記(エスケ?プ?シ?ケンスであってUTFではない!)を返してしまうのです。逆操作のescape()メソッドもこれに??します。ところが問題を更に複?にしているのが、IEのescape()??は通常のUTF-16のURLエンコ?ド(例えばj2sdk1.4のURLEncoder.encode(str, “UTF-16”);)とは全く異なる?なるユニコ?ド表記の文字列をつくりだす、ということなのです。例えば次のようなhtmファイルをIEで開くと、
<HTML>
<HEAD>
<TITLE>JavaScript escape()/unescape() functionarity test</TITLE>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=SHIFT_JIS">
</TITLE>
<BODY>
<PRE>
JavaScriptにおけるescape??のブラウザによる相違をチェックする
<SCRIPT LANGUAGE="JavaScript">
s="?閣?理大臣=小泉純一?";
document.writeln("original string : "+s);
s=escape(s);
document.writeln("escaped string : "+s);
s=unescape(s);
document.writeln("unescaped string : "+s);
</SCRIPT>
</PRE>
</BODY>
</HTML>
JavaScriptにおけるescape??のブラウザによる相違をチェックする
original string : ?閣?理大臣=小泉純一?
escaped string : %u5185%u95A3%u7DCF%u7406%u5927%u81E3%3D%u5C0F%u6CC9%u7D14%u4E00%u90CE
unescaped string : ?閣?理大臣=小泉純一?
つまり%u????なるユニコ?ドの16進表記を返していることがお分かりでしょう。
次のように、IEがunescape()??を使って?み出せないかとURLEncoder.encode()メソッドを使ってサ?バ側で、cookieをセットしたとしましょう。
import java.io.*;
import java.net.*;
import javax.servlet.*;
import javax.servlet.http.*;
/** クッキ??み書きサ?ブレット **/
public class HelloCookie extends HttpServlet {
public void doGet (HttpServletRequest req, HttpServletResponse res) throws ServletException, IOException {
PrintWriter out;
Cookie[] cookies;
Cookie cookie;
String urlencoding = "UTF-16"; //必要に?じ"Shift_JIS"や”UTF-8”などを試す
// Cookieの取得
cookies = req.getCookies();
cookie = null;
if (cookies != null){
for(int i=0; i < cookies.length; i++) {
cookie = cookies[i];
if (cookie.getName().equals("HelloCookie")) { break; }
}
}
res.setContentType("text/html; charset=Shift_JIS");
out = res.getWriter();
if (cookie == null) { // Cookieの書?み
String namestring = "?閣?理大臣";
String valuestring = "小泉純一?";
namestring = URLEncoder.encode(namestring, urlencoding);
valuestring = URLEncoder.encode(valuestring, urlencoding);
cookie = new Cookie(namestring, valuestring);
cookie.setMaxAge(300); // 有?期間は5分で切れる
res.addCookie(cookie);
out.println("<html><body>");
out.println("<h1>Write Cookie</h1>");
out.println("<P>");
out.println("<SCRIPT LANGUAGE="JavaScript">");
out.println("s=unescape(document.cookie);");
out.println("document.write("unescaped cookie : "+s);");
out.println("</SCRIPT>");
out.println("</P>");
out.println("<p>リロ?ドしてください。</p>");
out.println("</body></html>");
} else { // Cookieの表示
out.println("<html><body>");
out.println("<h1>");
out.println(URLDecoder.decode(cookie.getValue(), urlencoding));
out.println("</h1>");
out.println("<p>Cookieのサンプル(HelloCookie.java)</p>");
out.println("</body></html>");
}
}
}
このときtelnetでアクセスしてTomcatが送信するHTTP?答パケットのSet-Cookie行を調べると次のようになっています。
Set-Cookie: %FE%FF%51%85%95%A3%7D%CF%74%06%59%27%81%E3=%FE%FF%5C%0F%6C%C9%7D
%14%4E%00%90%CE;Expires=Wed, 23-Oct-2002 04:33:23 GMT
つまり「?閣?理大臣」の文字列は%FE%FF%51%85%95%A3%7D%CF%74%06%59%27%81%E3に、「小泉純一?」の文字列は%FE%FF%5C%0F%6C%C9%7D%14%4E%00%90%CEに?換されています。FEFFなる文字列はこれがBOM(バイト順マ?ク)で、ビッグエンディアンであることを意味します。これが正式のUTF-16コ?ド表示なのです。「?閣?理大臣=小泉純一?」という文字列の場合は次のように?換されます。
%FE%FF%51%85%95%A3%7D%CF%74%06%59%27%81%E3%00%3D%5C%0F%6C%C9%7D%14%4E%00%90%CE
?然のことながらこのサ?ブレットの出力をIEの unescape()??は正しく受け付けてはくれません。
IEが作り出す「?閣?理大臣=小泉純一?」のエンコ?ディングはさきほど示したように?なるユニコ?ド表記の
%u5185%u95A3%u7DCF%u7406%u5927%u81E3%3D%u5C0F%u6CC9%u7D14%u4E00%u90CE
であって、これとは全く異なっています。おまけに”=”という文字はユニコ?ド表示されないで?なる%3DというASCII文字として?理されてしまっています。どうして%u003Dとしないのでしょうか。ECMA-262に準?したもののようですが、困ったものです。したがって「IEの場合は怪しげなescape()とunescape()??は使わないほうが良い」というのが結論です。
ちなみに先ほどのサ?ブレットで String urlencoding = "Shift_JIS";と?更して、これをNNで呼び出すと次のように正常に表示されます。
但しNNではShift_JISのURLエンコ?ドを使っていれば問題がないかというと?念ながらそうではありません。例えば「?閣?理大臣 小泉純一?」と間に半角スペ?ス文字が入っているとNNは「?閣?理大臣+小泉純一?」とプラス記?に?えてしままいます。これはURLエンコ?ドの解?の相違によるもので、j2sdk1.4ではスペ?スは”+”文字に?換するのに、NNのescape()??の場合はスペ?スを%20に?換します。細かいことですがj2sdk1.4では?て統一して%nnの形式で?換するのにNNのescape()??の場合はバイトに直したときに危?な文字でなければそのまま1バイト文字として?換します。具?的に"?閣?理大臣 小泉純一?"なる文字列の?換の相違を示すと:
J2sdk1.4のURLEncoder.encode()
%93%E0%8A%74%91%8D%97%9D%91%E5%90%62
+%8F%AC%90%F2%8F%83%88%EA%98%59
NNのJavaScriptのescape()
%93%E0%8At%91%8D%97%9D%91%E5%90b
%20%8F%AC%90%F2%8F%83%88%EA%98Y
以上のことからJavaScriptのescape()とunescape()はIEとNN?方に問題があり、Webアプリのようにサ?バ/IE/NNともに問題なく情報交換させようとするとこれらの??は使うべきでない、と結論されます。
4. JavaScriptにおけるencodeURI、decodeURI、encodeURIComponent、decodeURIComponent
バ?ジョン
代表的なブラウザ
備考
1.0
NN2.0 の途中~
IE3.0
JavaScript のオリジナルの仕?
1.1
NN3
IE3.02+JScript1.3パッチ
Array objectやイベントなどの追加
1.2
NN4.0 ~ 4.05
IE4
Layer/DIV 機能, CSSの追加
1.3
NN4.06 ~
IE5.0 ~
unicodeなど主に ECMA-262??
1.4
NN5( 開?中止 )
catch/try 等の例外?理など( ECMA-262?? )
1.5
Mozilla5( NN6 )
IE6~
ECMA-262 3rd Edition
2.0
?
ECMA-262 4th Edition
encodeURI
元の文字列
IE6の出力
NN7の出力
?閣?理大臣小泉純一?
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
%20%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
%20%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
?閣?理大臣X小泉純一?
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
X%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
X%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
encodeURIComponent
元の文字列
IE6の出力
NN7の出力
?閣?理大臣小泉純一?
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
%20%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
%20%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
?閣?理大臣X小泉純一?
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
X%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
%E5%86%85%E9%96%A3%E7%B7
%8F%E7%90%86%E5%A4%A7%E8%87%A3
X%E5%B0%8F%E6%B3%89%E7
%B4%94%E4%B8%80%E9%83%8E
カテゴリ
文字
予約文字
, / ? : @ & = + $ ,
エスケ?プしない文字
アルファベット, 10進?字, - _ . ! ~ * ' ( )
スコア
#
したがってdocument.cookieでとりだした文字列をそのまま?すときはdecodeURI()を使うことになります。クッキ?の「値」や「名前」を?理するときはdecodeURIComponent()などを使うとしています。これはJavaScriptがクッキ?を(名前、値)のオブジェクトの集合ではなく、?なる文字列として取り扱かったため生じた問題です。これもまたプログラマに混?を?える要因になります。いずれはそのように改定されることになるでしょう。
ちなみに:
” %E5%86%85%E9%96%A3%E7%B7%8F%E7%90%86%E5%A4%A7%E8%87%A3%20%E5%B0%8F%E6%B3%89%E7%B4%94%E4%B8%80%E9%83%8E”
なる文字列は、decodeURI()もdecodeURIComponent()も同じ” ?閣?理大臣=小泉純一?”をかえします。
しかしながら、互換性の問題があるのです。つまりj2sdk1.4のURLencoder.encode(String,”UTF-8”)がエスケ?プする文字セットと、encodeURIのエスケ?プする文字セットが異なるのです。更に、j2sdk1.4でURLエンコ?ドした文字列がdecodeURI??では正しく?み取れないことになるのです。
encodeURI??がエスケ?プしない文字は下表のようでした。
カテゴリ
文字
予約文字
, / ? : @ & = + $ ,
エスケ?プしない文字
アルファベット, 10進?字, - _ . ! ~ * ' ( )
スコア
#
EncodeURIComponent??のほうはエスケ?プしない文字列には予約文字が含まれないのが違うところです。
しかしながら、j2sdk1.4のURLencoder.encode(String,”UTF-8”)がエスケ?プしない文字は下表のようになっています。赤字且つ斜め文字の部分がエスケ?プしない文字、但しスペ?ス(SP)は”+”に置き換え且つそれはエスケ?プしない文字です。
Char Decimal Hex Char Decimal Hex
NUL 0 0 SOH 1 1
STX 2 2 ETX 3 3
EOT 4 4 ENQ 5 5
ACK 6 6 BEL 7 7
BS 8 8 HT 9 9
NL 10 a VT 11 b
NP 12 c CR 13 d
SO 14 e SI 15 f
DLE 16 10 DC1 17 11
DC2 18 12 DC3 19 13
DC4 20 14 NAK 21 15
SYN 22 16 ETB 23 17
CAN 24 18 EM 25 19
SUB 26 1a ESC 27 1b
FS 28 1c GS 29 1d
RS 30 1e US 31 1f
SP 32 20 ! 33 21
" 34 22 # 35 23
$ 36 24 % 37 25
& 38 26 ' 39 27
( 40 28 ) 41 29
* 42 2a + 43 2b
, 44 2c - 45 2d
. 46 2e / 47 2f
0 48 30 1 49 31
2 50 32 3 51 33
4 52 34 5 53 35
6 54 36 7 55 37
8 56 38 9 57 39
: 58 3a ; 59 3b
< 60 3c = 61 3d
> 62 3e ? 63 3f
@ 64 40 A 65 41
B 66 42 C 67 43
D 68 44 E 69 45
F 70 46 G 71 47
H 72 48 I 73 49
J 74 4a K 75 4b
N 78 4e O 79 4f
P 80 50 Q 81 51
R 82 52 S 83 53
T 84 54 U 85 55
V 86 56 W 87 57
X 88 58 Y 89 59
Z 90 5a [ 91 5b
92 5c ] 93 5d
^ 94 5e _ 95 5f
` 96 60 a 97 61
b 98 62 c 99 63
d 100 64 e 101 65
f 102 66 g 103 67
h 104 68 i 105 69
j 106 6a k 107 6b
l 108 6c m 109 6d
n 110 6e o 111 6f
p 112 70 q 113 71
r 114 72 s 115 73
t 116 74 u 117 75
v 118 76 w 119 77
x 120 78 y 121 79
z 122 7a { 123 7b
| 124 7c } 125 7d
~ 126 7e DEL 127 7f
?って??サ?ブレットのプログラムで、
String namestring = "URLエンコ?ドの??";
String valuestring = " !"#$%&'()*+"+'u002c'+"-./01289:;<=>?@ABCXYZ[]"+'u005e'+'u005f'+'u0060'+"abcxyz{|}"+'u007e';
namestring = URLEncoder.encode(namestring, urlencoding);
valuestring = URLEncoder.encode(valuestring, urlencoding);
として、’u0020’から’u007e’までの文字がどのようにURLエンコ?ドされ、且つJavaScriptのdecodeURI??がどのようにデコ?ドするかを試してみると次のような結果が得られます。
undecoded cookie : URL%E3%82%A8%E3%83%B3%E3%82%B3%E3%83%BC%E3%83%89%E3%81%AE%E5%AE%9F%E9%A8%93
=+%21%22%23%24%25%26%27%28%29*%2B%2C-.%2F01289%3A%3B%3C%3D%3E%3F%40ABCXYZ%5B%5C%5D%5E_%60
abcxyz%7B%7C%7D%7E
decoded cookie : URLエンコ?ドの??=+!"%23%24%%26'()*%2B%2C-.%2F01289%3A%3B<%3D>%3F%40ABCXYZ[]^_`abcxyz{|}~
つまりdecodeURI??は予約文字とスコア文字へのデコ?ドはせず、そのままエスケ?プ表示を返してしまっているのです。?際はencodeURIでエスケ?プしない文字へのデコ?ド?てが非デコ?ドの?象となります。
「これらの文字を使わない」というのもひとつの解決法かも知れないが、あまり良い手段とはいえません。
また、クッキ?を一括エンコ?ドする場合はencodeURIComponent??を使ってはいけないことも忘れないで下さい。
5. それでは一?どうすればよいか?
現?では?念ながらencodeURI、decodeURI、encodeURIComponent、decodeURIComponentといった??が使えないブラウザが未だ多く利用されている現?であること、これらの??がJava 2プラットホ?ムのURLエンコ?ドとの互換性がないことを勘案して、cookieとJavaScriptを使ってクライアント/サ?バ間で情報交換する場合にはどうしたらよいのでしょうか?結局つぎのような結論となります。
結論
JavaScriptがサ?バがセットしたクッキ?を?理するようなアプリケ?ションにおいては:
1) クッキ?の名前と値ともにURLエンコ?ドすることが推?されるが、名前は「危?」でない(URLエンコ?ドに影響されない)文字からなる英?文字列に限定すべきです。telnetなどのツ?ルによる??やデバッグの便を配慮したものです。
2) NN及びIEのescape()とunescape()??は問題があるので使ってはなりません。EncodeURI()、decodeURI()、encodeURIComponent()、decodeURIComponent()も、古いバ?ジョンのブラウザでは??できていないし、j2sdk1.4との互換性の問題があります。結局J2sdk1.4のjava.netのパッケ?ジにあるURLEncoder.encode()及びURLDecoder.decode()と同じ機能を持ったJavaScriptの??を用意するのがベストです。そうすれば自分がどのブラウザ上のどのバ?ジョンで走っているかをJavaScriptは識別する必要もなくなります。
URLエンコ?ドはUTF-8に統一する。これはEncodeURI()、decodeURI()、encodeURIComponent()、decodeURIComponent()がUTF-8を使っているからという理由です。またJavaの仕?においてもUTF-8を推?しています。日本語では極めて?率が?いのですが、この世界ではUTF-8を標準的に使ったほうが無難でしょう。
6. UTF-8のURLエンコ?ド?デコ?ド??の例:
ユニコ?ド(1バイト、2バイト長、4バイト長がある)を外部とバイト列としてやり取りする形式(Unicode Transfer Format: UTF)にはUTF-8とUTF-16が良く使われます。今回はUTF-8によるURLエンコ?ドを?討するので、UTF-8へのURL?換法を紹介します。このまま使えとは申しません。このプログラムを?考にしていただければ幸いです。
UCSからUTF-8への?換法は次のテ?ブルに示したようになります。
UCSからUTF-8への?換法
UCS-2 (UCS-4)
ビットパタ?ン
第1バイト
第2バイト
第3バイト
第4バイト
U+0000 ..
U+007F
00000000-0xxxxxxx
0xxxxxxx
U+0080 ..
U+07FF
00000xxx-xxyyyyyy
110xxxxx
10yyyyyy
U+0800 ..
U+FFFF
xxxxyyyy-yyzzzzzz
1110xxxx
10yyyyyy
10zzzzzz
U+10000..
U+1FFFFF
00000000-000wwwxx-
xxxxyyyy-yyzzzzzzz
11110www
10xxxxxx
10yyyyyy
10zzzzzz
この形式の特?は1バイト文字以外は一番上のビット(MSB)がゼロにならないことで、一番上のビットがゼロの文字は7ビットASCII文字セットそのものだということです。したがって?換のアルゴリズムは極めて簡?です。URL?換に際しては1バイト形式以外の形式では必ず各バイトは%hhとエスケ?プ形式となります。
java.net.URLencoder.encode(String,”UTF-8”)に相?した??をJavaScriptで?現する際は、次のようなアルゴリズムになります。
もしその文字が'u0020’なら、それを'u002b’に置き換える
そうでなければ、
もしその文字が'u002a’、'u002d’、'u002e’、'u0030’??'u0039’、 'u0042’??
'u005a’、'u005f’、'u0061’??'u007a’でなければ
その文字をUTF-8?換し、各バイトを%XXのエスケ?プ文字列に?換する
java.net.URLdecoder.decode(String,”UTF-8”)に相?した??のアルゴリズムは;
もしその文字が'+’なら、それを' ’に置き換える
それ以外の文字で、
もしその文字がエスケ?プ文字列だったらこれをUTF-8?換だとしてユニコ?ド文字に?す
(それ以外の文字はそのまま)
と簡?なものです。
以下にその??と、??用HTMLを示します。これらの??は??の?張4バイト長ユニコ?ド(UCS-4)にも??しています。このHTMLファイルをブラウザで開くと次のような結果が得られるでしょう。
JavaScriptによるJ2プラットフォ?ム互換URLエンコ?ド??とそのテスト
original string : ?閣?理大臣 小泉純一? !"#$%&'()*+,-./01289:;<=>?@ABCXYZ[]^_`abcxyz{|}~
URL encoded string : %e5%86%85%e9%96%a3%e7%b7%8f%e7%90%86%e5%a4%a7%e8%87%a3+%e5%b0%8f%e6%b3%89%e7%b4%94%e4%b8%80%e9
%83%8e+%21%22%23%24%25%26%27%28%29*%2b%2c-.%2f01289%3a%3b%3c%3d%3e%3f%40ABCXYZ%5b%5c%5d%5e_%60
abcxyz%7b%7c%7d%7e
URL decoded string : ?閣?理大臣 小泉純一? !"#$%&'()*+,-./01289:;<=>?@ABCXYZ[]^_`abcxyz{|}~
?際のアプリケ?ションにおいては:
ア) ウェブ?サ?バ側は「値」の文字列をjava.net.URLEncoder.encode(String, “UTF-8”)を使ってURLエンコ?ドしてクッキ?の「値」にセットする
イ) ブラウザはWindow.document.cookieで取り出した文字列を
(ア) 「名前」と「値」に危?な文字が含まれていなければそのまま新しいdecodeURL()にかけるか、
(イ) 「値」の文字列をdecodeURL()にかけるか
して正しい文字列に?すことになります。
ウ) Window.document.cookieを?更する場合は、新しいencodeURL()??をつかって逆の操作をします。但しWindow.document.cookieに何か新しい「名前」の文字列を代入するということは、今までのクッキ?に新しいクッキ?が追加される(「名前」が同じならその「値」が書き換えられます。)ことになることに注意しましょう。
?考:
クッキ?の中から所定の名前の値を抽出する??の例です。
function loadCookie(name) {
var allcookies = document.cookie;
if (allcookies == "") return "";
var start = allcookies.indexOf(name + "=");
if (start == -1) return "";
start += name.length + 1;
var end = allcookies.indexOf(';',start);
if (end == -1) end = allcookies.length;
return allcookies.substring(start,end);
}
クッキ?の「値」がURLエンコ?ドされている場合は、
var decodedValue = decodeURL("loadCookie(name);
のようにデコ?ドします。また「名前」や「値」に予約語が含まれていないことがはっきりしている場合は
var allcookies = decodeURL("document.cookie);
という一括?理の使い方も可能です。
プログラム例
<HTML>
<HEAD>
<TITLE>j2 platform equivalent URL encode/decode functions</TITLE>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=SHIFT_JIS">
</TITLE>
<SCRIPT LANGUAGE="JavaScript">
/* Function Equivalent to java.net.URLEncoder.encode(String, "UTF-8")
Copyright (C) 2002, Cresc Corp.
Version: 1.0
*/
function encodeURL("str){
var s0, i, s, u;
s0 = ""; // encoded str
for (i = 0; i < str.length; i++){ // scan the source
s = str.charAt(i);
u = str.charCodeAt(i); // get unicode of the char
if (s == " "){s0 += "+";} // SP should be converted to "+"
else {
if ( u == 0x2a || u == 0x2d || u == 0x2e || u == 0x5f || ((u >= 0x30) && (u <= 0x39)) || ((u >= 0x41) && (u <= 0x5a)) || ((u >= 0x61) && (u <= 0x7a))){ // check for escape
s0 = s0 + s; // don't escape
}
else { // escape
if ((u >= 0x0) && (u <= 0x7f)){ // single byte format
s = "0"+u.toString(16);
s0 += "%"+ s.substr(s.length-2);
}
else if (u > 0x1fffff){ // quaternary byte format (extended)
s0 += "%" + (oxf0 + ((u & 0x1c0000) >> 18)).toString(16);
s0 += "%" + (0x80 + ((u & 0x3f000) >> 12)).toString(16);
s0 += "%" + (0x80 + ((u & 0xfc0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
else if (u > 0x7ff){ // triple byte format
s0 += "%" + (0xe0 + ((u & 0xf000) >> 12)).toString(16);
s0 += "%" + (0x80 + ((u & 0xfc0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
else { // double byte format
s0 += "%" + (0xc0 + ((u & 0x7c0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
}
}
}
return s0;
}
/* Function Equivalent to java.net.URLDecoder.decode(String, "UTF-8")
Copyright (C) 2002, Cresc Corp.
Version: 1.0
*/
function decodeURL("str){
var s0, i, j, s, ss, u, n, f;
s0 = ""; // decoded str
for (i = 0; i < str.length; i++){ // scan the source str
s = str.charAt(i);
if (s == "+"){s0 += " ";} // "+" should be changed to SP
else {
if (s != "%"){s0 += s;} // add an unescaped char
else{ // escape sequence decoding
u = 0; // unicode of the character
f = 1; // escape flag, zero means end of this sequence
while (true) {
ss = ""; // local str to parse as int
for (j = 0; j < 2; j++ ) { // get two maximum hex characters for parse
sss = str.charAt(++i);
if (((sss >= "0") && (sss <= "9")) || ((sss >= "a") && (sss <= "f")) || ((sss >= "A") && (sss <= "F"))) {
ss += sss; // if hex, add the hex character
} else {--i; break;} // not a hex char., exit the loop
}
n = parseInt(ss, 16); // parse the hex str as byte
if (n <= 0x7f){u = n; f = 1;} // single byte format
if ((n >= 0xc0) && (n <= 0xdf)){u = n & 0x1f; f = 2;} // double byte format
if ((n >= 0xe0) && (n <= 0xef)){u = n & 0x0f; f = 3;} // triple byte format
if ((n >= 0xf0) && (n <= 0xf7)){u = n & 0x07; f = 4;} // quaternary byte format (extended)
if ((n >= 0x80) && (n <= 0xbf)){u = (u << 6) + (n & 0x3f); --f;} // not a first, shift and add 6 lower bits
if (f <= 1){break;} // end of the utf byte sequence
if (str.charAt(i + 1) == "%"){ i++ ;} // test for the next shift byte
else {break;} // abnormal, format error
}
s0 += String.fromCharCode(u); // add the escaped character
}
}
}
return s0;
}
</SCRIPT>
</HEAD>
<BODY>
<PRE>
JavaScriptによるJ2プラットフォ?ム互換URLエンコ?ド??とそのテスト
<SCRIPT LANGUAGE="JavaScript">
s = "?閣?理大臣 小泉純一?" + " !"#$%&'()*+" + 'u002c'+ "-./01289:;<=>?@ABCXYZ[]" + 'u005e' + 'u005f' + 'u0060' + "abcxyz{|}" + 'u007e';
document.writeln("original string : "+s);
s = encodeURL("s);
document.writeln("URL encoded string : "+s);
s = decodeURL("s);
document.writeln("URL decoded string : "+s);
</SCRIPT>
</PRE>
</BODY>
</HTML>
7. JSPとJavaScript間のクッキ?によるデ?タ交換例
最後に皆さんが?際にサ?バのプログラムを作成される際の?考として、JSPとJavaScript間でテキストをクッキ?を介してやり取りするサンプルをお示しします。
このJSPをブラウザがアクセスすると次のような?面が得られるはずです。
動作は次のようです:
1. 最初にユ?ザはテキストエリアに任意のテキストを入力し、「クッキ?書?みと送信」のボタンを押すと、そのテキストはURLエンコ?ドされたのち”userdata”という「名前」の「値」としてクッキ?にセットされサ?バに送られます。
2. サ?バはクライアントから送られてきたクッキ?の?容のすべてを先ず「名前」/「値」のセットとしてクライアントへのHTMLテキストに書き?みます。その際「値」のほうはURLデコ?ドしたものを括弧でくくって一?に書き?みます。
3. サ?バは”userdata”という「名前」の「値」の部分をURLデコ?ドしたユ?ザからのテキストを再度URLエンコ?ドしてクッキ?にセットします。
4. クライアントのほうは、サ?バからのHTMLテキストを表示すると共に、一?に送られてきたJavaScriptにより受信したクッキ?の?容を生で表示し、次に”userdata”の「値」の部分をURLデコ?ドして表示します。
5. 送信したテキストと送り返されてきたテキストが一致すれば、正しく交信が出?たことになります。
本?にクッキ?がサ?バとクライアント?方で書き?んでいるか心配ですか?URLエンコ?ドされたクッキ?の「値」を見てください。エスケ?プされた文字がJavaScriptのほうは小文字の16進表示、JSPのほうは大文字の16進表示になっています。これはJavaScriptのNumber.toString(16)メソッドが小文字で出力するのに?し、Java 2プラットホ?ムのURLEncoder.encode(String,”UTF-8”)なるメソッドは大文字で出力するからです。これで?方のURL?理??が機能し、かつ互換性が取れていることが確認されます。
なお、復?や改行も入力できますので試してください。HTMLではこれらの文字は表示されませんが、正しくエンコ?ド?理されていることがわかります。ブラウザの設定によっては復?(CR: %0d)と改行(NL: %0a)?方がクッキ?に入る場合もありますし、改行のみの場合もありますので改行?理には注意が必要です。
以下にJSPペ?ジを紹介します。JSPのなかにJavaScriptも入っているので?みづらいところは我慢してください。JSPのプログラム部分を赤で、JavaScriptの部分を?で色分けしてあります。このプログラムを?際に??したのち、?んで頂くと理解が早いと思います。
<%@ page contentType="text/html; charset=Shift_JIS" session="true"
import="java.net.*" %>
<% Cookie[] cookies;
Cookie cookie;
cookies = request.getCookies();
cookie = null;
if (cookies != null){
for (int i = 0; i < cookies.length; i++){
cookie = cookies[i];
if (cookie.getName().equals("userdata")){break;}
}
String encodedUserData = cookie.getValue();
String decodedUserData = URLDecoder.decode(encodedUserData, "UTF-8");
cookie = new Cookie("userdata", URLEncoder.encode(decodedUserData, "UTF-8"));
cookie.setMaxAge(300); // give 5 minute to survive for the cookie
response.addCookie(cookie);
}
%>
<HTML>
<HEAD>
<TITLE>JavaScript j2 platform equivalent URL encode/decode functions and their test</TITLE>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=SHIFT_JIS">
</TITLE>
<SCRIPT LANGUAGE="JavaScript">
/* Function Equivalent to URLEncoder.encode(String, "UTF-8")
Copyright (C) 2002 Cresc Corp.
Version: 1.0
*/
function encodeURL("str){
var s0, i, s, u;
s0 = ""; // encoded str
for (i = 0; i < str.length; i++){ // scan the source
s = str.charAt(i);
u = str.charCodeAt(i); // get unicode of the char
if (s == " "){s0 += "+";} // SP should be converted to "+"
else {
if ( u == 0x2a || u == 0x2d || u == 0x2e || u == 0x5f || ((u >= 0x30) && (u <= 0x39)) || ((u >= 0x41) && (u <= 0x5a)) || ((u >= 0x61) && (u <= 0x7a))){ // check for escape
s0 = s0 + s; // don't escape
}
else { // escape
if ((u >= 0x0) && (u <= 0x7f)){ // single byte format
s = "0"+u.toString(16);
s0 += "%"+ s.substr(s.length-2);
}
else if (u > 0x1fffff){ // quaternary byte format (extended)
s0 += "%" + (oxf0 + ((u & 0x1c0000) >> 18)).toString(16);
s0 += "%" + (0x80 + ((u & 0x3f000) >> 12)).toString(16);
s0 += "%" + (0x80 + ((u & 0xfc0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
else if (u > 0x7ff){ // triple byte format
s0 += "%" + (0xe0 + ((u & 0xf000) >> 12)).toString(16);
s0 += "%" + (0x80 + ((u & 0xfc0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
else { // double byte format
s0 += "%" + (0xc0 + ((u & 0x7c0) >> 6)).toString(16);
s0 += "%" + (0x80 + (u & 0x3f)).toString(16);
}
}
}
}
return s0;
}
/* Function Equivalent to URLDecoder.decode(String, "UTF-8")
Copyright (C) 2002 Cresc Corp.
Version: 1.0
*/
function decodeURL("str){
var s0, i, j, s, ss, u, n, f;
s0 = ""; // decoded str
for (i = 0; i < str.length; i++){ // scan the source str
s = str.charAt(i);
if (s == "+"){s0 += " ";} // "+" should be changed to SP
else {
if (s != "%"){s0 += s;} // add an unescaped char
else{ // escape sequence decoding
u = 0; // unicode of the character
f = 1; // escape flag, zero means end of this sequence
while (true) {
ss = ""; // local str to parse as int
for (j = 0; j < 2; j++ ) { // get two maximum hex characters to parse
sss = str.charAt(++i);
if (((sss >= "0") && (sss <= "9")) || ((sss >= "a") && (sss <= "f")) || ((sss >= "A") && (sss <= "F"))) {
ss += sss; // if hex, add the hex character
} else {--i; break;} // not a hex char., exit the loop
}
n = parseInt(ss, 16); // parse the hex str as byte
if (n <= 0x7f){u = n; f = 1;} // single byte format
if ((n >= 0xc0) && (n <= 0xdf)){u = n & 0x1f; f = 2;} // double byte format
if ((n >= 0xe0) && (n <= 0xef)){u = n & 0x0f; f = 3;} // triple byte format
if ((n >= 0xf0) && (n <= 0xf7)){u = n & 0x07; f = 4;} // quaternary byte format (extended)
if ((n >= 0x80) && (n <= 0xbf)){u = (u << 6) + (n & 0x3f); --f;} // not a first, shift and add 6 lower bits
if (f <= 1){break;} // end of the utf byte sequence
if (str.charAt(i + 1) == "%"){ i++ ;} // test for the next shift byte
else {break;} // abnormal, format error
}
s0 += String.fromCharCode(u); // add the escaped character
}
}
}
return s0;
}
/* Function to get cookie parameter value string with specified name
Copyright (C) 2002 Cresc Corp.
Version: 1.0
*/
function loadCookie(name) {
var allcookies = document.cookie;
if (allcookies == "") return "";
var start = allcookies.indexOf(name + "=");
if (start == -1) return "";
start += name.length + 1;
var end = allcookies.indexOf(';',start);
if (end == -1) end = allcookies.length;
return decodeURL("allcookies.substring(start,end);
}
/* Function to send the textarea data throuth cookie
Copyright (C) 2002 Cresc Corp.
Version: 1.0
*/
function sendThis(){
document.cookie="userdata="+encodeURL("document.inForm.text.value); //set data
window.location.reload(); // and reload this page
}
</SCRIPT>
</HEAD>
<BODY>
JavaScriptによるJ2プラットフォ?ム互換URLエンコ?ド??と、JSPによるそのテスト<BR>
(URLエンコ?ドされたクッキ?のパラメタを介したサ?ブレットとJavaScript間のデ?タの交換)<BR><BR>
<% if (cookies != null){ %>
<DIV STYLE="width: 50% word-break:break-all">
サ?バ?が受け取ったクッキ?(URLデコ?ド後):<BR><%
for (int i = 0; i < cookies.length; i++){ %>
名前=<%= cookies[i].getName() %><BR>
値=<%= cookies[i].getValue() %><BR>
(<%= URLDecoder.decode(cookies[i].getValue(), "UTF-8") %>)<BR>
<% }
} %>
</DIV>
<P STYLE="width: 50%">
クライアントが受け取ったクッキ?(URLエンコ?ドされている):<BR>
<SCRIPT LANGUAGE="JavaScript">
document.writeln(document.cookie);
</SCRIPT>
</P>
<P STYLE="width: 50%">
クライアント受信したクッキ?の中のデ?タ部分:<BR>
<SCRIPT LANGUAGE="JavaScript">
document.writeln(loadCookie("userdata"));
</SCRIPT>
</P>
サ?バに送信するテキストを書き?んで下さい:<BR>
<FORM NAME="inForm">
<TEXTAREA ROWS="3" COLS="60" WRAP="soft" NAME="text"></TEXTAREA><BR>
<INPUT TYPE="button" VALUE="クッキ?書?みと送信" ONCLICK="sendThis()">
</FORM>
</BODY>
</HTML>