

| sitelink1 | http://blog.naver.com/simtwolove?Redirec...0022013436 |
|---|---|
| sitelink2 | |
| sitelink3 | |
| sitelink4 | |
| sitelink5 | |
| extra_vars6 |
자료구조가 무엇인지는 본 블로그의 "자료구조알고리즘" 항목의
첫번째 글에 자료구조에 대한 설명이 대략 있음을 알린다.
Part4 연결리스트
--------------------------------------
자료구조의 4번째 장, 연결 리스트(링크드 리스트) 이다.
연결리스트는 정말 자주쓰이는 자료구조 중 하나이다.
먼저 그림으로 나타 내 보면
배열
[ ][ ][ ][ ][ ][ ][ ]
연결리스트
[] [] [] []
[] ─>[] ─>[] ─> []
처럼 나타 낼 수 있다.
즉, 연결 리스트는 요소들이 메모리의 도처에 흩어져서 존재하지만 링크에 의해 논리적으로 연결되어 있는 자료구조 라 할 수 있다.
즉, 두개의 칸을 만들고, 한칸에는 데이터를, 다른 한 칸에는 다음 데이터가 있는 곳을 가리키게 하여,
서로서로 연결한 상태를 만든 것이 연결리스트라 할 수 있다.
이 둘의 차이점은 배열의 요소 하나는 자신이 기억할 데이터값만을 가지는데 비해 연결 리스트의 요소인 노드는 데이터외에 연결 상태에 대한 정보인 링크를 추가로 가져야 한다는 점이 차이점이라면 차이점이라고 할 수 있다.
잠깐. 연결리스트는 하나의 타입의 데이터를 여러개 저장하는데, 이는 앞에서 공부한 동적배열과 상당히 흡사하며,
연결리스트와 동적배열 모두 데이타를 저장할 수 있는 가변 크기를 가지는 자료 구조이다.
(자료의 갯수에 따라 크기가 움직인 다는 것이다.)
즉, 동적배열과 연결리스트는 용도가 완전히 같아 서로 대체가 가능하지만,
구성하는 원리, 구현방법, 관리방법 등은 질적으로 다르다.
동적배열의 경우 배열 가운대에 자료를 입력할 때,
입력하려는 장소보다 뒤에있는 데이터는 전부 뒤로 한칸씩 밀어야 하는 상황이 된다.
즉,
배열[ 1 ][ 2 ][ 3 ][ 4 ][ 5 ][ 6 ][ ][ ] 에서
배열[ 1 ][ 7 ][ 2 ][ 3 ][ 4 ][ 5 ][ 6 ][ ] (7 삽입)
└한칸씩뒤로미룬다┘
가 된다는 소리이며, 마찬가지로 삭제시에도 한칸씩 앞으로 밀어야 하는
매우 번거로운 상태가 되기마련이다.
하지만, 연결리스트에선 이런 상황이 대체로 쉽게 해결이 되는데, 이유인 즉,
[1] [2] [3] [4]
[ ] ─>[ ] ─> [ ] ─> [ ] 라는 연결리스트에서
[1] [2] [3] [4]
[ ] ─>[ ] [ ] ─> [ ] (5 삽입)
↘ ↑
[5] │
[ ] ─┘
이 되기 때문이다!
아하! 라고 직감이 오리라고 믿는다.
이에 대해선 잠시 뒤 자세히 알아보자.
연결리스트 에선 자기 다음의 요소가 누구인지를 스스로 기억하고 있어야 흩어져 있는 노드들의 순서를 알 수 있는데 이 연결 정보를 저장하는 것이 바로 링크이다.
링크를 하나만 가지는 것을 단순 연결 리스트(Single Linked List)라고 하고 두 개의 링크를 가지는 것을 이중 연결 리스트(Double Linked List)라고 한다.
(이중 연결 리스트는 다음 강의에서 알아보도록 하며, 이 장에선 단순 연결 리스트에 대해 공부해보자.)
노드([자료] 와 [가리키는곳(링크)]을 합하여 노드라고 부른다.)를 구성하는
[자료] 는 저장하려는 자료의 타입,
[링크] 는 가리키는 곳인 포인터 타입으로 선언해야 하며,
보통
------------
struct Node
{
int value;
Node *prt;
};
------------
로 나타낸다.
단, 노드의 맨 처음과 맨 끝은 특별한 노드로써,
맨 처음의 노드는 head , 맨 끝의 노드는 tail 이라고 부르는데,
head 는, 일단 머리를 알아야 연속적으로 다음 노드를 찾을 수 있으므로 언제든지 참조할 수 있는 전역 변수로 선언하는 것이 일반적이며, 진입점이므로 대표노드라 할 수 있다.
tail 은, 제일 마지막 노드로써 아무것도 가리키지 않거나 또는 자기자신을 가리켜 노드의 순회를 마치게 한다.
즉, 연결리스트는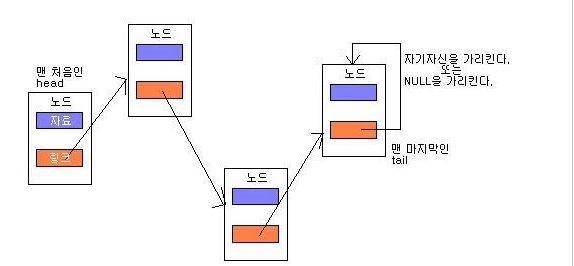
라고 할 수 있다.
노드들이 메모리상의 임의 위치에 생성된다는 것을 강조하기 위해 노드의 위치도 불규칙적으로 그렸다.
하지만 노드의 물리적인 위치가 어디인가는 전혀 중요하지 않으며 실제 번지에 상관없이 링크에 의해 서로 논리적으로 연결되어 있으므로 일직선으로 그리는 것이 보통이다.
마지막 tail의 링크가 자기자신을 가리키게 되어 있는데 (또는 NULL로) 무한루프에 빠진다는 것 (또는 다음 노드가 없다는 것)은 곳 연결 리스트의 끝이라는 뜻이다.
단, 머리 노드는 시작 노드의 번지만을 가지므로 데이터는 사용하지 않는다는 주의사항이 있다.
연결리스트의 소스는 다음과 같다.
//시작------------------------이 줄은 소스에 포함되지 않습니다.
- #include<stdio.h>
- #include<malloc.h>
- #include<stdlib.h>
- struct node
- {
- char data;
- struct node *ptr;
- };
- struct node *head, *tail;
- void addNode(char m)
- {
- struct node *NEW, *temp;
- NEW = (struct node *)malloc(sizeof(struct node));
- NEW->data = m;
- temp = head;
- while( temp->ptr != tail ) temp = temp->ptr;
- NEW->ptr = tail;
- temp->ptr = NEW;
- }
- void initNode()
- {
- head = (struct node *)malloc(sizeof(struct node));
- tail = (struct node *)malloc(sizeof(struct node));
- head->ptr = tail;
- }
- void printNode()
- {
- struct node *Now;
- for (Now=head->ptr;Now!=tail;Now=Now->ptr)
- {
- printf("%ct",Now->data);
- }
- }
- void eraseNode(char m)
- {
- struct node *del, *temp;
- temp = head;
- while( temp != tail )
- {
- del = temp->ptr;
- if( del->data == m)
- {
- temp->ptr = del->ptr;
- free(del);
- }
- temp = temp->ptr;
- }
- }
- int findNode(char m)
- {
- int i = 1;
- struct node *Now;
- for (Now=head->ptr;Now!=tail->ptr;Now=Now->ptr)
- {
- if(Now->data == m) return i;
- i++;
- }
- return 0;
- }
- void main()
- {
- char ch;
- int ch2;
- initNode();
- while(ch2 != 5)
- {
- printf("메뉴 추가:1 / 찾기:2 / 지우기:3n 출력:4 / 끝내기:5");
- scanf("%d",&ch2);
- switch(ch2)
- {
- case 1 :
- printf("추가할 데이타 입력");
- fflush(stdin);
- scanf("%c",&ch);
- addNode(ch);
- break;
- case 2 :
- printf("찾을 데이타 입력");
- fflush(stdin);
- scanf("%c",&ch);
- if(!findNode(ch))
- printf("없다n");
- else
- printf("%d번째에 있습니다n",findNode(ch));
- break;
- case 3 :
- printf("지울 데이타 입력");
- fflush(stdin);
- scanf("%c",&ch);
- eraseNode(ch);
- break;
- case 4 :
- printf("데이타를 출력합니다n");
- printNode();
- break;
- default:
- break;
- }
- }
- }
//끝------------------------이 줄은 소스에 포함되지 않습니다.
예상외로 간단하다.
이 소스를 차근차근 분석해 보자.
------------------------------
1. void addNode(char m);
struct node *NEW, *temp;
=> 새로 만들 NEW와 임시 저장용 temp 를 만든다.
temp에는 새로 만들 NEW의 전 노드를 가리킬 것이다.
(temp는 따로 만드는 것이 아니다. 단, NEW의 바로 이전의 노드를 temp라고 지칭하기만 할 것이다.)
NEW = (struct node *)malloc(sizeof(struct node));
NEW->data = m;
=> NEW에 새로 메로리를 부여하고, NEW의 데이타에 입력한 데이타 m을 넣는다.
temp = head;
while( temp->ptr != tail ) temp = temp->ptr;
=> temp는 맨 처음인 head 부터 맨 뒤인 tail이 아닐 때 까지
차근차근 다음노드, 그 다음노드, 그것의 다음노드로 이동한다.
NEW->ptr = tail;
temp->ptr = NEW;
=> 새로 추가한 노드는 마지막인 tail을 가리키고,
tail의 바로 전을 가리키던, 일명 temp라고 이름지은 이놈이 NEW를 가리킨다.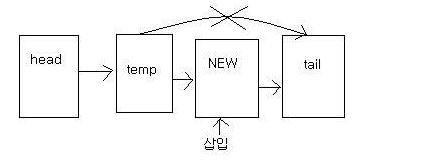
------------------------------
2. void initNode(char m)
큐, 스택과 마찬가지로 init는 초기화의 의미이다.
head = (struct node *)malloc(sizeof(struct node));
tail = (struct node *)malloc(sizeof(struct node));
=> head와 tail을 만들고 메모리를 부여한다.
head->ptr = tail;
=> head는 tail을 가리킨다.
(보통, head엔 데이타를 넣지 않는다!)
----------------------------
3. void printNode()
현재 모든노드의 데이타를 차례로 출력해 낸다.
struct node *Now;
=> 노드를 하나씩 이동해가며 데이타를 출력할 것이므로,
현재 노드를 가리킬 변수 하나를 선언한다.
for (Now=head->ptr;Now!=tail;Now=Now->ptr)
=> head가 가리키는 것 부터 (head의 다음것 부터) 왜냐하면, head에는 데이타가 없으니까.
tail이 아닐 때 까지 (끝이 아닐때 까지),
현재노드는 현재노드가 가리키는 것(다음 것)으로 이동해 가면서.
printf("%ct",Now->data);
=> 현재 노드의 데이타 출력.
-----------------------------
4. void eraseNode(char m)
노드를 삭제한다.
struct node *del, *temp;
=> 삭제할 노드를 가리킬 것 과, 삭제할 것의 전 노드를 가리킬 것을 선언
(del과 temp는 add()에서 temp와 마찬가지로 가리키기만 할 뿐이다.)
temp = head;
while( temp != tail ) { " 루프 " }
=> temp는 처음인 head부터, 마지막인 tail이 아닐 때 까지 아래의 루프를 반복한다.
del = temp->ptr;
=> del은 temp의 다음 것 (즉, del가 링크를 따라 이동한다)
(del은 삭제 할 노드를 가리키며, temp는 삭제 할 노드의 바로 이전 노드를 가리킨다.)
if( del->data == m)
{
temp->ptr = del->ptr;
free(del);
}
=> del 노드의 데이타와 삭제하려는 데이타가 같을 때,
del 이전의 노드 (temp)는 del 다음의 노드 를 가리키고,
del노드의 메모리를 해방 (free : 자유롭게 놓아준다) 시켜준다. 즉, 메모리를 삭제한다.
temp = temp->ptr;
=> temp는 링크를 따라 한칸 씩 이동하면서 while 루프를 반복한다.
삭제를 그림으로 나타내면 아래와 같다.
[1] [2] [3] [4]
[ ] ─>[ ] ─> [ ] ─> [ ] (3 삭제)
\__________↗
-----------------------
5. int findNode(char m)
해당 데이타를 자료로 가지는 노드가 몇번째 노드인지 찾아낸다.
int i = 1;
struct node *Now;
=> 루프를 돌기위한 i 선언,
현재를 가리킬 노드를 선언
(여기서도 마찬가지로 노드를 하나씩 이동하는데, 현재 검색하는 노드를 가리키기만 할 뿐이다.)
for (Now=head->ptr;Now!=tail->ptr;Now=Now->ptr)
=> Now는 head가 가리키는 곳부터 (즉, head의 다음 노드부터)
Now가 tail이 가리키는 곳이 아닐 때 까지, 즉 tail까지. (끝까지)
Now는 다음 링크를 따라 이동하면서.
!!--- 여기서 Now!=tail->ptr; 는, 단순히 Now; 로, 또는 Now!=NULL; 로도 쓸 수 있다. ---!!
if(Now->data == m) return i;
i++;
=> 현재 노드의 data가 찾으려는 데이타 이면 몇번째인지 i 리턴,
for 루프 돌때마다 i를 1씩 증가.
return 0;
=> 발견하지 못할 시 0 리턴.
------------------------------------------
연결리스트와 동적배열은 상당히 비슷하지만,
상당히 차이점도 크다.
가장 큰 차이점은 아무래도 삽입, 삭제가 빠르고 편리한 점이며,
또다른 차이점으론 동적배열에서 여러가지 데이타를 한꺼번에 다루려면
int a[ ][ ][ ][ ][ ]
float b[ ][ ][ ][ ][ ]
char c[ ][ ][ ][ ][ ]
에서 삽입 시 위 3개 중 a배열이 삽입하려는 곳 뒤의 자료들을 한칸씩 미루고,
b 배열이 삽입하려는 곳 뒤의 자료들을 한칸씩 미루고,
c 배열이 삽입하려는 곳 뒤의 자료들을 한칸씩 미루고,
삭제시 한칸 씩 앞으로 땡기는 뻘짓을 해야 하지만,
(속도가 매우 느리며 상당히 효율적이지 못하다.)
연결리스트에선
--------
struct Node
{
int a;
float b;
char c;
Node *prt;
};
-------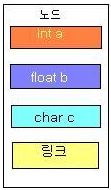
로 간단히 구현하여 링크끼리의 주고받기만 이용하면 된다.
또, 앞에서 배운 큐와 스택은 연결리스트를 이용하여 더욱 세련되게 구현할 수 있으며,
(큐와 스택의 배열이 꽉 차는 막강한 단점을 연결리스트를 이용하여 거의 무제한으로 늘린다.)
차후 공부할 트리에서도 연결리스트가 필요하므로,
반드시 연결리스트를 완벽히 마스터 하도록 하자!
-------------------
written by 호근
20420 선린 인터넷 고등학교.