

| sitelink1 | http://sysnet.pe.kr/220054582679 |
|---|---|
| sitelink2 | |
| sitelink3 | |
| sitelink4 | |
| sitelink5 | |
| extra_vars6 |
유니코드의 Surrogate Pair, Supplementary Characters가 뭘까요?
유니코드와 한글 - 유니코드와 닷넷을 이용한 한글 처리
; http://www.sysnet.pe.kr/2/0/1294
유니코드의 "compatibility character"가 뭘까요?
; http://www.sysnet.pe.kr/2/0/1607
위의 글도 읽어보시면 좋겠지요. ^^ 오늘은 유니코드의 Surrogate Pair, Supplementary Characters에 대한 용어를 설명해 보겠습니다.
혹시 여러분들은 2바이트 UTF-16 코드가 어떻게 6만 5천 글자를 넘어서는 글자들을 표현할 수 있는지에 대해 궁금하지 않으셨나요? 분명히 유니코드는 4바이트 영역을 쓰기로 작정한 문자셋이므로 16비트로 표현하기에는 역부족입니다. 바로 그 해결책이 Surrogate Pair입니다.
Surrogate Pair는 마이크로소프트의 MSDN 문서에 보면 다음과 같이 친절하게 설명되어 있습니다.
Surrogates and Supplementary Characters
; http://msdn.microsoft.com/en-us/library/windows/desktop/dd374069(v=vs.85).aspx
우선 Supplementary Characters는 유니코드의 2바이트 기본 범위에 속하는 BMP(Basic Multilingual Plane: Plane 0) 영역을 넘어선 글자들이라고 합니다. 그리고 Surrogate Pair는 이 범주에 속하는 Supplementary Characters를 표현하기 위해 UTF-16에 도입된 인코딩 방식입니다.
^^ 그러고 보니, 아래의 글에서도 Surrogate Pair에 해당하는 문자를 다루고 지나갔었습니다.
유니코드와 한글 - 유니코드와 닷넷을 이용한 한글 처리
; http://www.sysnet.pe.kr/2/0/1294
바로 U+10000 과 U+10001 2개의 글자가 Surrogate Pair 방식으로 표현되었던 것입니다.
Unicode Character 'LINEAR B SYLLABLE B008 A' (U+10000)
; http://www.fileformat.info/info/unicode/char/10000/index.htm
Unicode Character 'LINEAR B SYLLABLE B038 E' (U+10001)
; http://www.fileformat.info/info/unicode/char/10001/index.htm
위의 2개 문자를 보면 값이 2바이트 영역을 넘어서고 있습니다. 즉, U+10000 과 U+10001 글자들은 Supplementary Characters에 해당합니다. 그리고 해당 문자들을 표현하기 위해 각각 다음과 같이 2개의 UTF-16 코드가 할당되어 있습니다.
U+10000: \uD800 \uDC00
U+10001: \uD800 \uDC01
여기서 왜 "Pair"라고 하는지 밝혀집니다. 즉, 2바이트 영역을 넘어서는 글자 하나를 표현하기 위해 2개의 2바이트가 사용된 것입니다.
그런데, 위의 0xd800, 0xdc00, 0xdc01 코드로 이미 기존에 할당된 문자들과는 그럼 어떻게 구분한다는 말입니까? 물론, 코드를 아무거나 사용할 수는 없지요. 그래서 원래 UTF-16인코딩에서 U+D800 ~ U+DFFF 사이의 2048 글자 영역은 비어 있었습니다. 그리고 이를 절반씩 1024개로 나눠서 pair의 앞글자와 뒷글자 영역을 담당하게 한 것입니다. 즉, surrogate pair는 다음의 쌍으로 이뤄집니다.
[0xd800 ~ 0xdbff] [0xdc00 ~ 0xdfff]
Pair의 앞 글자에 1024개의 경우의 수가 나오고 뒤의 글자에도 역시 1024개의 경우의 수가 나오므로 이를 조합하면 1,048,576으로 약 100만개의 글자 영역이 확보되는 것입니다. 일단, 기존의 6만 개가 넘는 글자에 100만개의 글자 영역이 추가로 확보되었으니 당분간은 외계 언어가 추가되지 않는 한 UTF-16으로 충분히 문자를 표현할 수 있을 정도는 된 것입니다. 실제로 "Surrogates and Supplementary Characters" 글에 보면 유니코드 4.1에서 9만 7천자 정도가 추가된 정도라고 합니다. (정확히 하면 UTF-16은 현재 1,114,112개의 글자를 표현할 수 있다고 합니다.)
그럼, Supplementary Characters가 자신의 컴퓨터에서 어떻게 보여질 수 있는지 간단하게 테스트를 해볼까요? ^^ (윈도우 기준으로 하겠습니다.)
우선 차이점을 느끼기 위해 현재의 환경에서 다음의 웹 페이지를 Internet Explorer (또는 Chrome)로 방문해 봅니다.
Using UTF-16 Little-Endian Plane 1 Supplementary Characters
; http://www.i18nguy.com/unicode/plane1-utf-16.html
그럼, IE 11의 경우 다음과 같이 "Linear B Syllabary", "Shavian" 영역의 글자가 비정상적으로 나오는 것을 볼 수 있습니다.
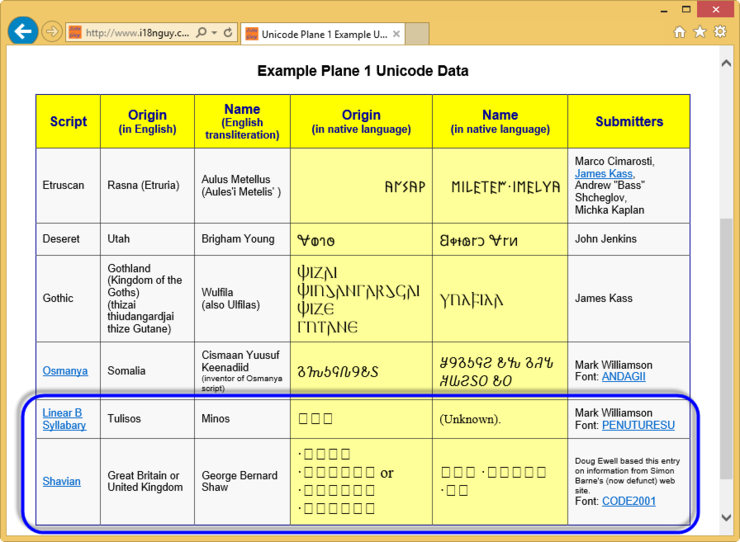
크롬의 경우는 다음과 같이 전체가 비정상적으로 나옵니다.
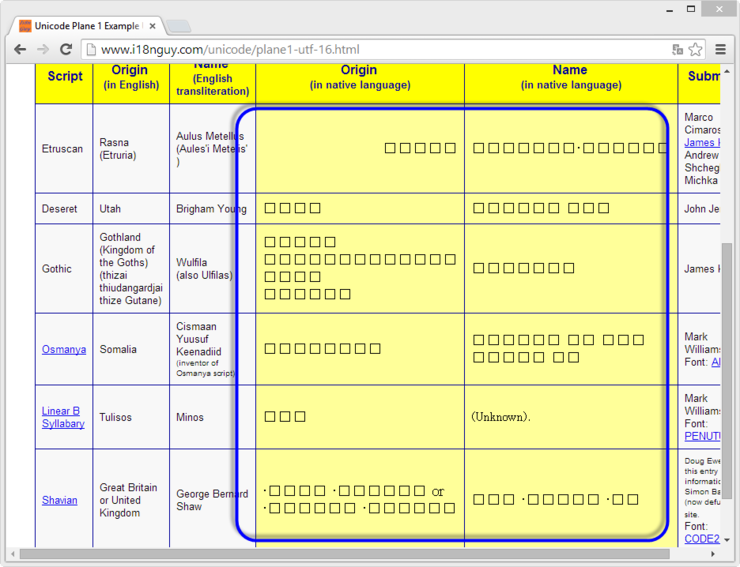
IE와 크롬의 차이는 아마도 웹 페이지에 포함된 "Arial Unicode MS" 폰트의 로드 차이인 것 같습니다.
td.plane1 {
font-family : CODE2001, "Arial Unicode MS", serif;
font-size : 120%;
text-align : left;
direction : ltr;
color : black;
background-color : #FFFF99;
}
IE의 경우 기본적으로 일부 유니코드를 보여줄 수 있는 "Arial Unicode MS" 폰트를 로드할 수 있는 반면 크롬은 (왠일인지?) 로드를 하지 않는 것 같습니다.
자, 그럼 이 페이지들을 정상적으로 보이기 위한 설정을 해볼까요? ^^
우선, 여러분들이 만약 윈도우 운영체제를 XP/2003이하의 버전을 쓰고 있다면 3가지 레지스트리 설정을 선행해서 처리해야 합니다. 어떤 설정인지는 다음의 글을 참고하시면 됩니다.
Setting up Microsoft Windows NT, 2000 or Windows XP to support Unicode supplementary characters
; http://www.i18nguy.com/surrogates.html
(중간에 보면, "Setting 1", "Setting 2", "Setting 3"의 레지스트리 설정이 나오는데 이를 참고하시면 됩니다.)
저는 윈도우 8.1에서 테스트 하고 있기 때문에 위의 설정을 하지 않았습니다. 그 다음, 웹 브라우저가 사용할 수 있는 폰트를 시스템에 등록해야 합니다.
위의 CSS 코드에 보면 "CODE2001"이라는 폰트 명을 볼 수 있는데요. 바로 이것을 여러분들의 윈도우 시스템에 설치해야 합니다. 아쉽게도 "Using UTF-16 Little-Endian Plane 1 Supplementary Characters" 글에 링크된 "http://home.att.net/~jameskass/CODE2001.ZIP" 파일은 현재 존재하지 않습니다. 어쩔 수 없이 웹 검색을 했는데 다음의 페이지에서 발견할 수 있었습니다.
Code2001 font - Created in 1998 by James Kass
; http://www.fontspace.com/james-kass/code2001
; http://www.fontspace.com/download/13285/2489492aa53d466d94ffc197bfe1a865/james-kass_code2001.zip
Code2001 is an experimental Plane 1 Unicode based font. The first 255 code points are as in ISO-8859-001. The balance of the code points are from Plane 1, a supplementary plane of Unicode.
다운로드 받아 압축을 풀고 "CODE2001.TTF" 파일을 탐색기에서 두번 누르면 폰트 창이 뜨는데, 상단의 "Install" 버튼을 누르면 윈도우(C:\Windows\Fonts)에 설치가 됩니다.
설치 후 인터넷 익스플로러는 재시작할 필요없이 페이지 로딩만 다시 하면 곧바로 유니코드 폰트가 보입니다. (크롬의 경우에는 종료한 후 다시 페이지를 방문해야 합니다.)
어쨌든, 두가지 웹 브라우저 모두 다음과 같이 1번 Plane 영역에 속한 "Supplementary Characters" 유니코드 문자를 잘 보여줍니다. ^^
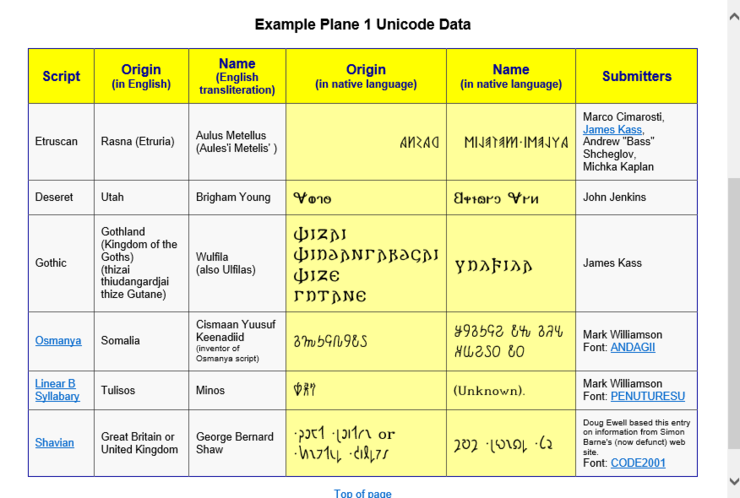
그럼, C# 응용 프로그램에서는 어떻게 해야 할까요?
"Surrogates and Supplementary Characters" 글에 의하면, "Edit", "Rich Edit" 컨트롤이 "Supplementary Characters"를 지원한다고 합니다.
테스트를 위해 윈폼 프로젝트를 하나 만들고, TextBox, RichTextBox를 각각 올려 놓은 후 Form1_Load에서 다음과 같이 코딩을 해봅니다.
private void Form1_Load(object sender, EventArgs e)
{
string text = "\uD800\uDF38";
// 또는 text = "