

| sitelink1 | https://blog.naver.com/rickman2/221406690459 |
|---|---|
| sitelink2 | |
| sitelink3 | |
| sitelink4 | |
| sitelink5 | |
| extra_vars6 |
자연어 처리(Natural Language Processing - NLP)
요즘 인공지능, 빅데이터가 부상하면서, 자연어 처리에 대한 관심이 높습니다. 그래서 이번엔 이에 대한 포스팅 수행하고자 합니다. 본 포스트는 그 첫번째로, 자연어 처리에 대한 기본적인 개념과, 그 중에서도 형태소 분석, 어간 추출에 대해서 알아보도록 하겠습니다.
1. 자연어 처리란?
자연어 처리는 우리가 사용하는 언어를 컴퓨터가 인식하여, 이를 처리할 수 있도록 하는 기술입니다. 즉 사람이 사용하는 언어와 컴퓨터가 사용하는 언어 사이에서 이를 인식할 수 있게 합니다. 특히 최근에는 이러한 접근방식에 인공지능 기술이 접목되면서 다양한 서비스가 개발되고 있습니다.
현재 여러분들도 관련된 서비스를 자주 이용 있으며(네이버, 구글 이런 검색서비스도 자연어 처리 기술임 - (이외에도 음성인식, 자동번역, 쳇봇, 검색엔진 등) 좀더 다양한 형태로 우리 생활에 다가오고 있습니다.
1-1 그럼 자연어 처리 과정은요?
http://www.aistudy.co.kr/linguistics/natural/natural_language_processing.htm
우선 위의 사아트에서 이와 관련하여 다음과 같은 내요을 조사해 보았습니다.
"자연어 처리는 크게 두 가지 작업으로 나눌 수 있다. 첫째는 실세계의 필요한 정보뿐만 아니라 언어에 있어서의 어휘, 구문, 의미에 관한 지식 (lexical, syntactic, semantic knowledge) 을 사용해서 문어 (written text) 를 처리하는 것이다. 둘째는 위에 더하여 음성에서 발생되는 애매함을 비롯한 음성학 (Phonology) 에 대한 부가적인 지식을 필요로하는 구어 (spoken language) 를 처리하는 것이다."
즉 하나의 측면은 문자로써의 역할로 이를 이해하는 것이고(파란색- 아래그림), 다른 하나는 언어, 특히 음성학을 영역(붉은색- 아래그림)을 포함해 처리하는 부분으로 구분된다는 것을 알 수 있습니다.
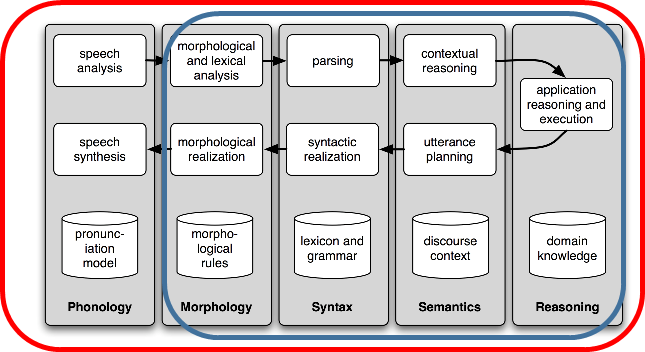
이제 파란색 부분을 좀더 구체적으로 표현하면 아래와 같이 표현해 볼 수 있습니다. 즉 입력을 문서가 입력되면, 전처리 과정에서, 언어를 탐지하고, 탐지된 언어를 기반으로 Tokenization, POS Tagging, Stop word를 처리하게 됩니다. 이후, Modeling 작업을 수행하여, 원하는 결과(감성분석, 분류, 요소추출, 번역, 토픽모델링 등)를 도출하는 과정이 자연어 처리입니다.
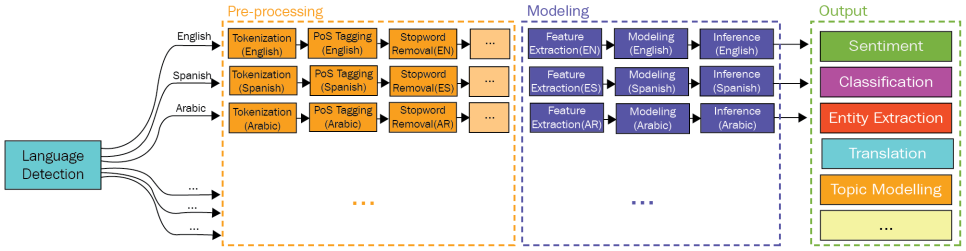
2. 토큰화 Tokenization
토큰화는 문서, 문단, 문장의 기본단위로 구분하는 작업입니다. 다시 말해서, 자연어 분석을 수행할 때 매우 중요한 절차입니다. 즉 문단 토큰화, 문장 토큰화, 단어 토큰화와 같이 기본 단위로 토큰화가 구분됩니다. 단어 토큰화의 경우 일반적으로 공백문자를 기준으로 합니다. 다면 이 경우, 예를들어 [문재인캠프], [문재인 캠프] 를 토큰화할 경우 다른 의미가 이뤄질 수 있습니다. 즉 전자 문재인캠프를 지칭하나 후자는 문재인, 캠프로 구분해서 토큰화하기 떄문입니다. 이외에도 토큰화에서 고려할 사항은 매우 다양합니다. 이러한 원인으로 다양한 토큰화 알고리즘들이 개발되어 있습니다.
또 고려할 점은 이러한 특징이 언어마다 다르다는 것입니다. 중국어의 경우에는 언어에 띄어쓰기가 없어서, 한글의 경우 띄어쓰기 규칙을 잘 지키지 않아서, 등 언어마나 고유의 특성을 가집니다. 그러므로 토큰 알고리즘을 앞서 언급한 바와 같이 다양한 점들을 고려해야만 합니다. 아래의 그림은 몇가지 토큰화 알고리즘을 나타낸 것입니다.
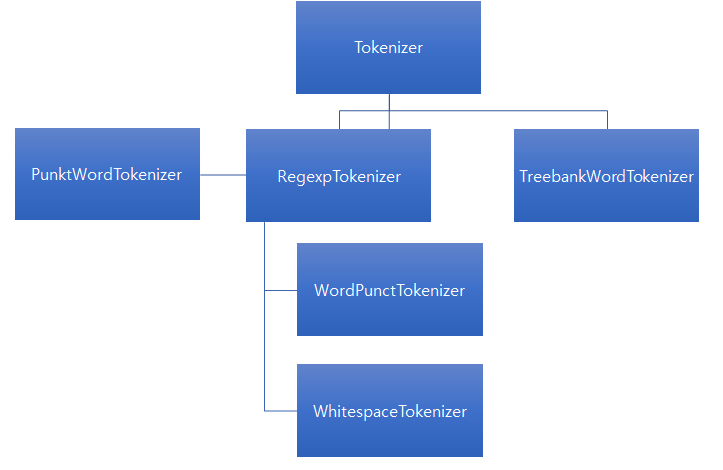
3. POS(Part Of Speach) Tagging
토큰으로 구분된 단어를 품사로 매칭되는 구조로 구분하고, 이를 기반으로 개체의 의미를 구분하는 과정을 가리킵니다. 즉 동사, 명사, 형용사, 조사 등으로 세분화해서 이를 각 단어를 기준으로 태킹을 붙이는 작업이죠. 보통 이 경우 해당 단어를 사전에 나타난 단위로 구분하고 이를 통해 품사를 태깅하게 됩니다. 그럼 이 과정이 필요한 이유는 무엇일까요?
예, 맞습니다. 품사도 큰 의미를 지니기 때문입니다. 명사인지, 동사인지, 형용사인지에 따라서 문장에서 아주 중요한 의미를 가지기도 하고, 이와는 반대로 그냥 꾸미는 정도의 의미만을 가질 수 있기 때문입니다. 그러므로 품사 태깅을 통해 이러한 의미를 부여해 데이터 활용에 중요한 정보로 활용합니다.
4. 불용어(Stopword)
불용어는 영어에서는 he, it, there 등 과 같은 대명사가 주로 처리됩니다. 즉, 문장의 구성에서 큰 의미를 가지지 않는 것들은 텍스트 분석의 요소에서 제거 하는 것이죠. 이러한 작업은 전처리 과정에서 주로 이뤄지게 됩니다. 일반적으로 검색엔진에서는 검색 공간을 줄이기 위해 불용어를 제거합니다. 불용어 제거는 자연어 처리의 매우 중요한 정규화 작업 중 하나입니다.
5. 이후과정
전처리 과정이 완료되면 실제 응용서비스의 목적에 부합되도록 전처리한 데이터를 기반으로 특징을 추출, 모델링, 추론 등을 통해를 결국 얻고자 하는 결과를 도출합니다. 이 부분이 향후 RNN, CNN 등과 같은 딥러닝 알고리즘이 이용되거나, 이외에도 다양한 기계학습 모델들이 이용되게 됩니다.
이번 포스트에서는 간단하게 자연어 처리에 대한 일반적인 과정에 대해서 살펴보았습니다. 이후 포스트에서는 하나하나씩 그 과정을 풀어보면서, 실제 자연어 처리를 어떻게 하면 되는지 실습과 이론을 다루면서 살펴보도록 하겠습니다.
마지막으로 관련 동영상 하나 보시고 마무리 하겠습니다.
